DataX
第一章 DataX概览
用户在互联网上进行的所有的操作,都会留下很多的数据。有些是用户的行为数据,例如用户在什么时间点启动了APP、什么时间点点击了某一个按钮、在某一个商品的详情页停留了30秒时间、收藏了某一篇文章、点赞了某一个评论等。这些数据会以服务器日志的形式记录下来。而有些数据是记录的业务数据,例如用户下单购买了什么商品等,这些数据一般会存储与关系型数据库中,例如MySQL或者Oracle。
对于大数据开发来说,我们需要处理的数据来自于很多的渠道,有一些是服务器的日志文件,有一些是服务端的业务数据。我们要做的第一件事情,就是将这些数据导入到我们的大数据平台,然后再对其进行计算、处理,得出我们希望的结果。而在数据采集的时候,我们可以自己开发采集的程序、脚本来实现,也可以使用一些开源的第三方的程序。例如:使用flume可以实现将服务器日志文件采集到HDFS进行存储,而对于关系型数据库的数据的采集同步,我们可以采用DataX来实现。
1.1. DataX是什么
DataX是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现了包括MySQL、SQLServer、Oracle、PostgreSQL、HDFS、Hive、HBase、OTS、ODPS等各种异构数据源之间高效的数据同步功能。
DataX本身作为数据同步框架,将不同数据源的同步抽象为从源头数据源读取数据的Reader插件,以及向目标端写入数据的Writer插件。理论上DataX框架可以支持任意数据源类型的数据同步工作。同时DataX插件体系作为一套生态系统,每接入一套新数据源时,这个新加入的数据源即可实现和现有的数据源互通。
1.2. DataX 3.0概览
DataX是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
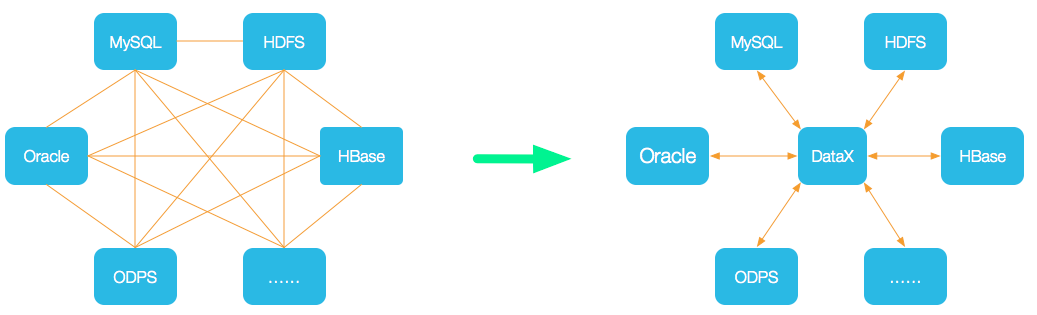
设计理念
为了解决异构数据源同步的问题,DataX将复杂的网状的同步链路变成了星型的链路。DataX作为中间传输载体,负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
当前使用现状
DataX在阿里巴巴集团内被广泛使用,承担了所有大数据的离线同步业务,并已持续稳定运行了6年之久。目前每天完成同步8W多道作业,每日传输数据量超过300TB。
此前已经开源DataX 1.0版本,此次介绍为阿里云开源全新版本DataX 3.0,有了更多更强大的功能和更好的使用体验。
GitHub主页地址: https://github.com/alibaba/DataX
第二章 DataX详解
2.1. DataX 3.0框架设计

DataX本身作为离线数据同步框架,采用FrameWork+plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
- **Reader: **Reader为数据采集模块,负责采集数据源的数据,将数据发送给FrameWork。
- **Writer: **Writer为数据写入模块,负责不断从FrameWork取数据,并将数据写入到目的端。
- FrameWork: FrameWork用于连接Reader和Writer,作为两者的数据传输通道,并处理缓冲、流控、并发、数据转换等核心技术问题。
2.2. DataX 3.0插件体系
DataX将数据源读取和写入抽象成为Reader/Writer插件,经过几年积累,DataX目前已经有了比较全面的插件体系,主流的RDBMS数据库、NOSQL、大数据存储系统都已经接入。DataX目前支持的数据源如下:
| 类型 | 数据源 | Reader(读) | Writer(写) | 文档 |
|---|---|---|---|---|
| RDBMS关系型数据库 | MySQL | √ | √ | 读、写 |
| Oracle | √ | √ | 读、写 | |
| OceanBase | √ | √ | 读、写 | |
| SQLServer | √ | √ | 读、写 | |
| PostgreSQL | √ | √ | 读、写 | |
| DRDS | √ | √ | 读、写 | |
| 达梦 | √ | √ | 读、写 | |
| 通用RDBMS(支持所有关系型数据库) | √ | √ | 读、写 | |
| 阿里云数仓数据存储 | ODPS | √ | √ | 读、写 |
| ADS | √ | 写 | ||
| OSS | √ | √ | 读、写 | |
| OCS | √ | √ | 读、写 | |
| NoSQL数据存储 | OTS | √ | √ | 读、写 |
| HBase0.94 | √ | √ | 读、写 | |
| HBase1.x | √ | √ | 读、写 | |
| HBase2.x | √ | √ | 读、写 | |
| MongoDB | √ | √ | 读、写 | |
| Hive | √ | √ | 读、写 | |
| 无结构化数据存储 | TxtFile | √ | √ | 读、写 |
| FTP | √ | √ | 读、写 | |
| HDFS | √ | √ | 读、写 | |
| Elasticsearch | √ | 写 | ||
| Clickhouse | √ | 写 |
DataXFrameWork提供了简单的接口与插件交互,提供简单的插件接入机制,只需要任意加上一种插件,就能无缝对接其他数据源
2.3. DataX 3.0核心架构
DataX3.0开源版本支持单机多线程模式完成同步作业运行,本小节按一个DataX作业生命周期的时序图,从整体架构设计,非常简要说明DataX各个模块相互关系。
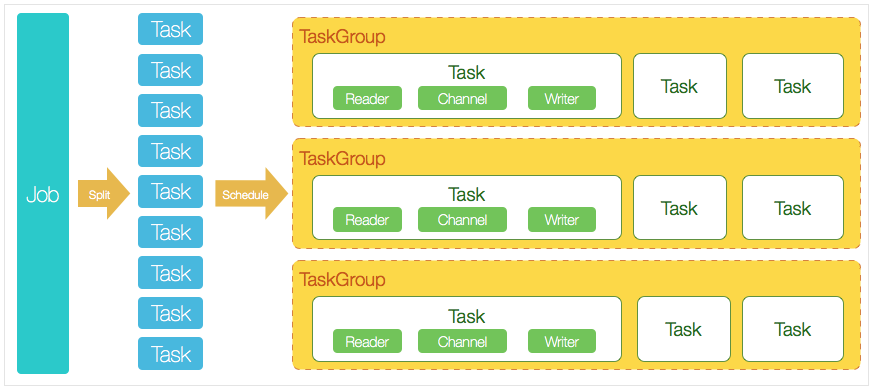
2.3.1. 核心模块介绍
- DataX完成单个数据同步的作业,我们称之为Job。DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataXJob模块是单个作业的中枢管理节点,承担了数据清洗、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
- DataXJob启动之后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
- 切分多个Task之后,DataXJob会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发度运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
- 每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader->Channel->Writer的线程来完成任务同步工作。
- DataX作业运行起来之后,Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后,Job成功退出。否则,异常退出,进程退出值非0。
2.3.2. DataX调度流程
举例来说,用户提交了一个DataX作业,并且配置了20个并发,目的是将一个100张分表的mysql数据同步到ODPS里面。DataX的调度决策思路是:
-
DataXJob根据分库分表切分成了100个Task。
-
根据20个并发,DataX计算共需要分配4个TaskGroup。
-
4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责以5个并发,共计运行25个Task。
理论上是每一个TaskGroup负责25个Task,但实际执行的过程中,每一个Task所需要处理的数据量是不同的,执行耗时也是不同的,所以有可能有的TaskGroup会分配的多一些,有些会分配的少一些。
2.4. DataX 3.0的六大核心优势
-
可靠的数据质量监控
-
完美解决数据传输个别类型失真问题
DataX旧版对于部分数据类型(比如时间戳)传输一直存在毫秒阶段等数据失真情况,新版本DataX3.0已经做到支持所有的强数据类型,每一种插件都有自己的数据类型转换策略,让数据可以完整无损的传输到目的端。
-
提供作业全链路的流量、数据量运行时监控
DataX3.0运行过程中可以将作业本身状态、数据流量、数据速度、执行进度等信息进行全面的展示,让用户可以实时了解作业状态。并可在作业执行过程中智能判断源端和目的端的速度对比情况,给予用户更多性能排查信息。
-
提供脏数据探测
在大量数据的传输过程中,必定会由于各种原因导致很多数据传输报错(比如类型转换错误),这种数据DataX认为就是脏数据。DataX目前可以实现脏数据精确过滤、识别、采集、展示,为用户提供多种的脏数据处理模式,让用户准确把控数据质量大关!
-
-
丰富的数据转换功能
DataX作为一个服务于大数据的ETL工具,除了提供数据快照搬迁功能之外,还提供了丰富数据转换的功能,让数据在传输过程中可以轻松完成数据脱敏,补全,过滤等数据转换功能,另外还提供了自动groovy函数,让用户自定义转换函数。详情请看DataX3的transformer详细介绍。
-
精准的速度控制
-
还在为同步过程对在线存储压力影响而担心吗?新版本DataX3.0提供了包括通道(并发)、记录流、字节流三种流控模式,可以随意控制你的作业速度,让你的作业在库可以承受的范围内达到最佳的同步速度。
"speed": { "channel": 5, "byte": 1048576, "record": 10000 }
-
-
强劲的同步性能
DataX3.0每一种读插件都有一种或多种切分策略,都能将作业合理切分成多个Task并行执行,单机多线程执行模型可以让DataX速度随并发成线性增长。在源端和目的端性能都足够的情况下,单个作业一定可以打满网卡。另外,DataX团队对所有的已经接入的插件都做了极致的性能优化,并且做了完整的性能测试。性能测试相关详情可以参照每单个数据源的详细介绍:DataX数据源指南
-
健壮的容错机制
DataX作业是极易受外部因素的干扰,网络闪断、数据源不稳定等因素很容易让同步到一半的作业报错停止。因此稳定性是DataX的基本要求,在DataX 3.0的设计中,重点完善了框架和插件的稳定性。目前DataX3.0可以做到线程级别、进程级别(暂时未开放)、作业级别多层次局部/全局的重试,保证用户的作业稳定运行。
-
线程内部重试
DataX的核心插件都经过团队的全盘review,不同的网络交互方式都有不同的重试策略。
-
线程级别重试
目前DataX已经可以实现TaskFailover,针对于中间失败的Task,DataX框架可以做到整个Task级别的重新调度。
-
-
极简的使用体验
-
易用
下载即可用,支持linux、windows、macOS,只需要短短几步骤就可以完成数据的传输。请点击:Quick Start
-
详细
DataX在运行日志中打印了大量信息,其中包括传输速度,Reader、Writer性能,进程CPU,JVM和GC情况等等。
-
传输过程中打印传输速度、进度等

-
传输过程中会打印进程相关的CPU、JVM等

-
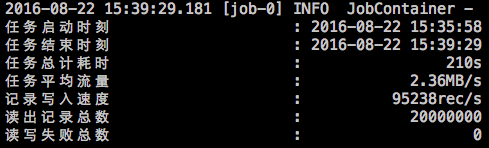
在任务结束之后,打印总体运行情况
-
-
第三章 Quick Start
3.1. 环境准备
- Linux操作系统
- JDK(1.8及其以上都可以,推荐1.8)
- Python(2或者3都可以)
- Apache Maven 3.x(源码编译安装需要)
3.2. 安装部署
3.2.1. 二进制安装
-
下载安装DataX工具包,下载地址:http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
-
将下载好的包上传到Linux中
-
解压安装即可
tar -zxvf datax.tar.gz -C /usr/local -
自检脚本
# python {YOUR_DATAX_HOME}/bin/datax.py {YOUR_DATAX_HOME}/job/job.json # 例如: python /usr/local/datax/bin/datax.py /usr/local/datax/job/job.json -
异常解决
如果执行自检程序出现如下错误:
[main] WARN ConfigParser - 插件[streamreader,streamwriter]加载失败,1s后重试... Exception:Code:[Common-00], Describe:[您提供的配置文件存在错误信息,请检查您的作业配置 .] - 配置信息错误,您提供的配置文件[/usr/local/datax/plugin/reader/._drdsreader/plugin.json]不存在. 请检查您的配置文件. [main] ERROR Engine - 经DataX智能分析,该任务最可能的错误原因是: com.alibaba.datax.common.exception.DataXException: Code:[Common-00], Describe:[您提供的配置文件存在错误信息,请检查您的作业配置 .] - 配置信息错误,您提供的配置文件[/usr/local/datax/plugin/reader/._drdsreader/plugin.json]不存在. 请检查您的配置文件. at com.alibaba.datax.common.exception.DataXException.asDataXException(DataXException.java:26) at com.alibaba.datax.common.util.Configuration.from(Configuration.java:95) at com.alibaba.datax.core.util.ConfigParser.parseOnePluginConfig(ConfigParser.java:153) at com.alibaba.datax.core.util.ConfigParser.parsePluginConfig(ConfigParser.java:125) at com.alibaba.datax.core.util.ConfigParser.parse(ConfigParser.java:63) at com.alibaba.datax.core.Engine.entry(Engine.java:137) at com.alibaba.datax.core.Engine.main(Engine.java:204)解决方案:将plugin目录下的所有的以_开头的文件都删除即可
cd /usr/local/datax/plugin find ./* -type f -name ".*er" | xargs rm -rf
3.2.2. 源码编译
# 1. 下载DataX源码
git clone git@github.com:alibaba/DataX.git
# 2. 通过maven打包
cd {DataX_source_code_home}
mvn -U clean package assembly:assembly -Dmaven.test.skip=true
# 3. 打包成功,显示日志如下
# [INFO] BUILD SUCCESS
# [INFO] -----------------------------------------------------------------
# [INFO] Total time: 08:12 min
# [INFO] Finished at: 2022-03-13T17:20:19+08:00
# [INFO] Final Memory: 133M/960M
# [INFO] -----------------------------------------------------------------
# 4. 打包成功后的DataX包位于 {DataX_source_code_home}/target/datax/datax/ ,结构如下:
# cd {DataX_source_code_home}
# ls ./target/datax/datax/
# bin conf job lib log log_perf plugin script tmp
3.2.3. python3支持
DataX这个项目本身是用Python2进行开发的,因此需要使用Python2的版本进行执行。但是我们安装的Python版本是3,而且3和2的语法差异还是比较大的。因此直接使用 python3 去执行的话,会出现问题。
如果需要使用 python3 去执行数据同步的计划,需要修改 bin 目录下的三个 py 文件,将这三个文件中的如下部分修改即可:
- print xxx 替换为 print(xxx)
- Exception, e 替换为 Exception as e
懒人直达版:直接下载我修改过后的,替换到
bin目录即可。链接: https://pan.baidu.com/s/1eGfmuBKZJN54YrNs-RWFRQ?pwd=7r7w 提取码: 7r7w
替换完成之后,如果自检脚本无法使用,只需要删除 plugin 目录下的所有以 _ 开头的文件即可
cd /usr/local/datax/plugin
find ./* -type f -name ".*er" | xargs rm -rf
3.3. 配置示例
3.3.1. 生成配置模板
DataX的数据同步工作,需要使用 json 文件来保存配置信息,配置writer、reader等信息。我们可以使用如下的命令来生成一个配置的json模板,在这个模板上进行修改,生成最终的json文件。
python3 /usr/local/datax/bin/datax.py -r -w
将其中的 替换成自己想要的reader组件名字,将其中的 替换成自己想要的writer组件名字。
-
支持的reader:
所有的reader都存储于DataX安装目录下的
plugin/reader目录下,可以在这个目录下查看cassandrareader、hbase094xreader、mongodbreader、odpsreader、otsreader、rdbmsreader、txtfilereader、drdsreader、hbase11xreader、mysqlreader、oraclereader、otsstreamreader、sqlserverreader、ftpreader、hdfsreader、oceanbasev10reader、ossreader、postgresqlreader、streamreader -
支持的writer:
所有的writer都存储于DataX安装目录下的
plugin/writer目录下,可以在这个目录下查看adswriter、ftpwriter、hbase11xwriter、mysqlwriter、odpswriter、otswriter、sqlserverwriter、cassandrawriter、hbase094xwriter、hdfswriter、oceanbasev10writer、oraclewriter、postgresqlwriter 、drdswriter、hbase11xsqlwriter、mongodbwriter、ocswriter、osswriter、rdbmswriter、txtfilewriter
例如需要查看 streamreader 和 streamwriter 的配置,可以使用如下操作
python3 /usr/local/datax/bin/datax.py -r streamreader -w streamwriter
这个命令可以将json模板直接打印在控制台上,如果想要以文件的形式保存下来,重定向输出即可
python3 /usr/local/datax/bin/datax.py -r streamreader -w streamwriter > ~/stream2stream.json
3.3.2. 创建配置文件
创建stream2stream.json文件
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"sliceRecordCount": 10,
"column": [
{
"type": "long",
"value": "10"
},
{
"type": "string",
"value": "hello,你好,世界-DataX"
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "UTF-8",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": 5
}
}
}
}
3.3.3. 启动DataX
python3 datax.py ./stream2stream.json
3.3.4. 结果显示
2022-07-04 16:23:53.906 [job-0] INFO JobContainer - PerfTrace not enable!
2022-07-04 16:23:53.906 [job-0] INFO StandAloneJobContainerCommunicator - Total 50 records, 950 bytes | Speed 95B/s, 5 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 100.00%
2022-07-04 16:23:53.907 [job-0] INFO JobContainer -
任务启动时刻 : 2022-07-04 16:23:43
任务结束时刻 : 2022-07-04 16:23:53
任务总计耗时 : 10s
任务平均流量 : 95B/s
记录写入速度 : 5rec/s
读出记录总数 : 50
读写失败总数 : 0
3.4. 动态传参
3.4.1. 动态传参的介绍
DataX同步数据的时候需要使用到自己设置的配置文件,其中可以定义同步的方案,通常为 json 的格式。在执行同步方案的时候,有些场景下需要有一些动态的数据。例如:
- 将MySQL的数据同步到HDFS,多次同步的时候只是表的名字和字段不同。
- 将MySQL的数据增量的同步到HDFS或者Hive中的时候,需要指定每一次同步的时间。
- ...
这些时候,如果我们每一次都去写一个新的 json 文件将会非常麻烦,此时我们就可以使用 动态传参
所谓的动态传参,就是在 json 的同步方案中,使用类似变量的方式来定义一些可以改变的参数。在执行同步方案的时候,可以指定这些参数具体的值。
3.4.2. 动态传参的案例
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"sliceRecordCount": $TIMES,
"column": [
{
"type": "long",
"value": "10"
},
{
"type": "string",
"value": "hello,你好,世界-DataX"
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "UTF-8",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": 1
}
}
}
}
在使用到同步方案的时候,可以使用 -D 来指定具体的参数的值。例如在上述的json中,我们设置了一个参数 TIMES,在使用的时候,可以指定TIMES的值,来动态的设置 sliceRecordCount 的值。
python3 /usr/local/datax/bin/datax.py -p "-DTIMES=3" parameter.json
3.5. 并发设置
在DataX的处理流程中,Job会被划分成为若干个Task并发执行,被不同的TaskGroup管理。在每一个Task的内部,都由 reader -> channel -> writer 的结构组成,其中 channel 的数量决定了并发度。那么channel的数量是怎么指定的?
- 直接指定channel数量
- 通过
Bps计算channel数量 - 通过
tps计算channel数量
3.5.1. 直接指定
在同步方案的json文件中,我们可以设置 job.setting.speed.channel 来设置channel的数量。这是最直接的方式。在这种配置下,channel的 Bps 为默认的 1MBps,即每秒传输 1MB 的数据。
3.5.2. Bps
Bps(Byte per second)是一种非常常见的数据传输速率的表示,在DataX中,可以通过参数设置来限制总Job的Bps以及单个channel的Bps,来达到限速和channel数量计算的效果。
$channel = {Job \: Bps \over channel \: Bps}$
- **Job Bps:**对一个Job进行整体的限速,可以通过
job.setting.speed.byte进行设置 - **channel Bps:**对单个channel的限速,可以通过
core.transport.channel.speed.byte进行设置
3.5.3. tps
tps(transcation per second)是一种很常见的数据传输速率的表示,在DataX中,可以通过参数设置来限制总Job的tps以及单个channel的tps,来达到限速和channel数量计算的效果。
$channel = {Job\;tps \over channel\;tps}$
- **Job tps:**对一个Job进行整体的限速,可以通过
job.setting.speed.record进行设置 - **channel tps:**对单个channel的限速,可以通过
core.transport.channel.speed.record进行设置
3.5.4. 优先级
- 如果同时配置了 Bps 和 tps 限制,以小的为准。
- 只有在 Bps 和 tps 都没有配置的时候,才会以 channel 数量配置为准。
第四章 常用插件
4.1. Stream
4.1.1. streamreader
介绍
streamreader是DataX内置的一个插件,用来读取数据源的数据内容。通常情况下是读取内存中的一些数据。
streamreader读取内存中的数据,数据是以列为单位组织起来。
参数说明
| 参数 | 描述 |
|---|---|
| column | 定义内存数据的所有的列。由一个JSON组成,需要定义数据与类型。 |
| sliceRecordCount | 每个channel中,数据重复的数量。 |
数据类型
在定义每一个列的数据的时候,需要指定每一列的数据的类型。DataX中支持如下的数据类型:
- Long
- Double
- String
- Date
- Boolean
- Bytes
配置样例
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column": [
{"value": "hello world", "type": "string"},
{"value": "datax", "type": "string"},
{"value": 123, "type": "long"}
],
"sliceRecordCount": 1
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print": true
}
}
}
]
}
}
4.1.2. streamwriter
介绍
streamwriter是DataX内置的一个插件,用来承接Framework的数据,保存在内存中,后面可以将其输出在控制台。
参数说明
| 参数 | 描述 |
|---|---|
| 将内存中的数据打印在控制台上。 | |
| encoding | 输出数据使用的字符集,默认是UTF-8。 |
配置样例
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column": [
{"value": "hello world", "type": "string"},
{"value": "datax", "type": "string"},
{"value": 123, "type": "long"}
],
"sliceRecordCount": 1
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print": true
}
}
}
]
}
}
4.2. Text
4.2.1. txtfilereader
介绍
txtfilereader提供了读取本地文件系统数据存储的能力。在底层实现上,txtfilereader获取本地文件数据,并转换为DataX传输协议传递给Writer。
txtfilereader实现了从本地文件读取数据并转换为DataX协议的功能,本地文件本身是无结构化数据存储。目前txtfilereader支持的功能如下:
- 支持且仅支持读取txt的文件,且要求txt中schema为一张二维表
- 支持类csv格式文件,自定义分隔符
- 支持多种类型数据读取(使用String表示),支持列裁剪,支持列常量
- 支持递归读取,支持文件名过滤
- 支持文本压缩,现有压缩格式为zip、gzip、bzip2
- 多个文件可以支持并发读取
参数说明
| 参数 | 描述 | 必选 | 默认值 |
|---|---|---|---|
| path | 本地文件系统的路径信息,注意这里可以支持填写多个路径。 当指定单个本地文件,txtfilereader暂时只能使用单线程进行数据抽取;当指定多个本地文件,txtfilereader可以使用多线程进行数据抽取。线程并发数通过通道数指定。 当指定通配符时,txtfilereader尝试遍历出多个文件信息。例如:指定/*代表读取/目录下的所有文件。txtfilereader目前只支持使用*作为文件通配符。 特别需要注意:DataX会将一个作业下同步的所有的文件视为同一张数据表。用户必须自己保证所有的文件能够适配同一套Schema信息。读取文件用户必须保证为类csv格式,并且提供给DataX权限可读。 特别需要注意:如果path指定的路径下没有符合的文件,DataX将报错。 | 是 | 无 |
| column | 读取字段列表 type:指定源数据的类型,必须要指定。 index:指定当前列来自于文本第几列(从0开始),与value选择其一指定。 value:指定当前类型为常量,不从源文件读取数据,而是根据value值自动生成对应的列。 | 是 | 全部按照string类型读取 |
| fieldDelimiter | 读取文件的字段分隔符 | 是 | , |
| compress | 文件压缩类型,支持的压缩类型为zip、gzip、bzip2 | 否 | 无压缩 |
| encoding | 读取文件的编码配置 | 否 | utf-8 |
| skipHeader | 类csv格式文件可能存在表头为标题,需要跳过 | 否 | false |
| nullFormat | 文本文件中无法使用标准字符串定义null,DataX提供nullFormat定义哪些字符串可以表示为null。例如用户配置 nullFormat: "\N",那么如果读取到的源文件是"\N",DataX将视为null字段。 | 否 | \N |
配置样例1
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "txtfilereader",
"parameter": {
"path": "/root/datax-data/person*",
"column": [
{"type": "string", "index": 0},
{"type": "long", "index": 1},
{"type": "string", "index": 2},
{"type": "double", "index": 3},
{"type": "double", "index": 4},
{"type": "long", "index": 5}
],
"fieldDelimiter": ",",
"nullFormat": "null"
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print": true
}
}
}
]
}
}
配置样例2
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "txtfilereader",
"parameter": {
"path": "/root/datax-data/student.csv.gz",
"column": [
{"type": "string", "index": 0},
{"type": "long", "index": 1},
{"type": "long", "index": 2}
],
"fieldDelimiter": "|",
"nullFormat": "null",
"skipHeader": true,
"compress": "gzip"
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print": true
}
}
}
]
}
}
4.2.2. txtfilewriter
介绍
txtfilewriter插件提供了向本地文件系统写入类csv格式的一个或者多个文件,写入本地的内容存放的是一张逻辑意义上的二维表,例如csv格式的文本信息。txtfilewriter实现了从DataX协议转为本地txt文件功能,本地文件本身是无结构化数据存储。
- 支持且仅支持写入txt的文件,且要求txt中schema为一张二维表
- 支持类csv格式文件,自定义分隔符
- 支持文本压缩,现有压缩格式为gzip、bzip2
- 支持多线程写入,每个线程写入不同的文件
参数说明
| 参数 | 描述 | 必选 | 默认值 |
|---|---|---|---|
| path | 本地文件系统的路径信息,txtfilewriter会写入path目录下多个文件 | 是 | 无 |
| fileName | txtfilewriter写入的文件名,该文件名会添加随机的后缀作为每个线程写入实际文件名 | 是 | 无 |
| writeMode | txtfilewriter写入钱数据清理处理模式: truncate:写入前清理目录下fileName前缀的所有文件 append:写入前不做任何处理,直接使用filename写入,并保证文件名不冲突 nonConflict:如果目录下有fileName前缀的文件,直接报错 | 是 | 无 |
| fieldDemiliter | 字段的分隔符 | 否 | , |
| compress | 文本压缩类型,支持的压缩类型为zip、tgz、bzip2、lzo、lzop | 否 | 无压缩 |
| encoding | 文件的编码格式 | 否 | utf-8 |
| nullFormat | 如果遇到了null,使用什么内容来填充 | 否 | \N |
| dateFormat | 日期类型的数据写出的格式 | 否 | 无 |
| fileFormat | 文件写出的格式 | 否 | text |
| header | 写出文件的表头,例如["id", "name", "age"] | 否 | 无 |
配置样例1
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column": [
{"value": "hello world", "type": "string"},
{"value": 123, "type": "long"},
{"value": 123, "type": "long"},
{"value": 98, "type": "long"}
],
"sliceRecordCount": 2
}
},
"writer": {
"name": "txtfilewriter",
"parameter": {
"path": "/root/datax-output/",
"fileName": "txtfilewriter-out",
"writeMode": "truncate",
"fieldDelimiter": ","
}
}
}
]
}
}
配置样例2
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column": [
{"value": "xiaobai", "type": "string"},
{"value": 173, "type": "long"},
{"value": 77, "type": "long"},
{"value": 98, "type": "long"}
],
"sliceRecordCount": 2
}
},
"writer": {
"name": "txtfilewriter",
"parameter": {
"path": "/root/datax-output/",
"fileName": "txtfilewriter-out",
"writeMode": "truncate",
"fieldDelimiter": ",",
"nullFormat": "NULL",
"compress": "gzip",
"header": ["name", "height", "weight", "age"]
}
}
}
]
}
}
4.3. MySQL
4.3.1. mysqlreader
介绍
MySQLReader插件实现了从MySQL读取数据,在底层实现上,MySQLReader通过JDBC远程连接MySQL数据库,并执行相应的SQL语句,将数据从MySQL数据库中查询出来。
简而言之,MySQLReader通过JDBC连接器连接到远程的MySQL数据库,并根据用户配置的信息生成查询的SQL语句,然后发送到远程MySQL数据库,并将该SQL执行返回结果使用DataX自定义的数据离线拼装为抽象的数据集,并传递给下游Writer处理。
对于用户配置Table、Column、Where的信息,MySQLReader将其拼接成为SQL语句发送到MySQL数据库;对于用户配置QuerySQL信息,MySQLReader直接将其发送到MySQL数据库。
参数说明
| 参数 | 描述 | 必选 | 默认值 |
|---|---|---|---|
| jdbcUrl | 描述的是到对端数据库的JDBC连接信息,使用JSON的数组描述,并支持一个库填写多个连接地址。之所以使用JOSN数组描述连接信息,是因为阿里集团内部支持多个IP探测,如果配置了多个,MySQLReader可以依次探测IP的可连接性,直到选择一个合法的IP。如果全部连接失败,MySQLReader报错。注意,jdbcUrl必须包含在connection配置单元中。对于阿里集团外部使用情况,JSON数组填写一个JDBC连接即可。 | 是 | 无 |
| username | 连接到数据库的用户名 | 是 | 无 |
| password | 连接到数据库的密码 | 是 | 无 |
| table | 所选取的需要同步的标。使用JSON的数组描述,因此支持多张表同时抽取。当配置为多张表时,用户自己需保证多张表是同一schema结构,MySQLReader不予检查表是否同一逻辑表。注意,table必须包含在connection的配置单元中。 | 是 | 无 |
| column | 所配置的表中需要同步的列名集合,使用JSON数组描述字段信息。用户使用*代表默认使用所有列配置。 支持列裁剪,即列可以挑选部分列进行导出。 支持列换序,即列可以不按照表schema信息进行导出。 支持常量配置,用户需要按照MySQL语法格式。 ["id", "`table`", "1", "'bazhen.csy'", "null", "to_char(a + 1)", "2.3" , "true"] id为普通列名,`table`为包含保留字的列名,1为整形数字常量,'bazhen.csy'为字符串常量,null为空指针,to_char(a + 1)为表达式,2.3为浮点数,true为布尔值。 | 是 | 无 |
| splitPk | MySQLReader进行数据抽取时,如果指定splitPk,表示用户希望使用splitPk代表的字段进行数据分片,DataX因此会启动并发任务进行数据同步,这样可以大大提高数据同步的效能。 推荐splitPk用户使用表主键,因为表主键通常情况下比较均匀,因此切分出来的分片也不容易出现数据热点。 目前splitPk仅支持整型数据切分,不支持浮点、字符串、日期等其他类型。如果用户指定其他非支持类型,MySQLReader将报错。 如果splitPk不填写,包括不提供splitPk或者splitPk为空,DataX视作使用单通道同步该表数据。 | 否 | 无 |
| where | 筛选条件,MySQLReader根据指定的Column、table、where条件拼接SQL,并根据这个SQL进行数据抽取。在实际业务场景中,往往会选择当天的数据进行同步,可以将where的条件指定为 gmt_create > $bizdate 。注意:不可以将where条件指定为limit 10,因为limit不是SQL的合法where子句。 | 否 | 无 |
| querySql | 在有些业务场景下,where这一配置项不足以描述所筛选的条件,用户可以通过该配置型来自定义筛选SQL。当用户配置了这个选项后,DataX就会忽略column配置项,直接使用这个配置项的内容对数据进行筛选,例如需要进行多表join后同步数据。 当用户配置querySQL的时候,MySQLReader直接忽略column、where条件的配置,querySql的优先级大于column、where选项。querySql和table不能同时存在 | 否 | 无 |
类型转换
下面是MySQLReader与MySQL的类型比较
| DataX内部类型 | MySQL数据类型 |
|---|---|
| Long | int, tinyint, smallint, medium, int, bigint |
| Double | float, double, decimal |
| String | varchar, char, tinytext, text, mediumtext, longtext, year |
| Date | date, datetime, timestamp, time |
| Boolean | bit, bool |
| Bytes | tinyblob,mediumblob, blob, longblob, varbinary |
配置样例1
配置一个从MySQL数据库同步抽取数据到本地的作业
{
"job": {
"setting": {
"speed": {
"channel": 3
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123456",
"column": ["empno", "ename", "job"],
"splitPk": "empno",
"connection": [
{
"table": ["emp"],
"jdbcUrl": ["jdbc:mysql://qianfeng01:3306/mydb"]
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print": true
}
}
}
]
}
}
配置样例2
配置一个自定义SQL的数据库同步任务到本地内容的作业
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123456",
"connection": [
{
"querySql": ["select * from emp where comm is not null;"],
"jdbcUrl": ["jdbc:mysql://qianfeng01:3306/mydb"]
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print": true,
"encoding": "UTF-8"
}
}
}
]
}
}
异常解决
读取MySQL的数据是通过JDBC来读取的,因此需要有对应的jar包。datax内置的驱动包的版本是5.1.34,版本比较老旧。如果你的MySQL数据库的版本为8以上,那么这个版本的驱动包是不合适的。因此可能会出现连接失败的异常。
解决方案:找到适合版本的驱动包,替换掉内置的驱动包即可。
datax内置的MySQL的驱动包的路径: $DATAX_HOME/plugin/reader/mysqlreader/libs
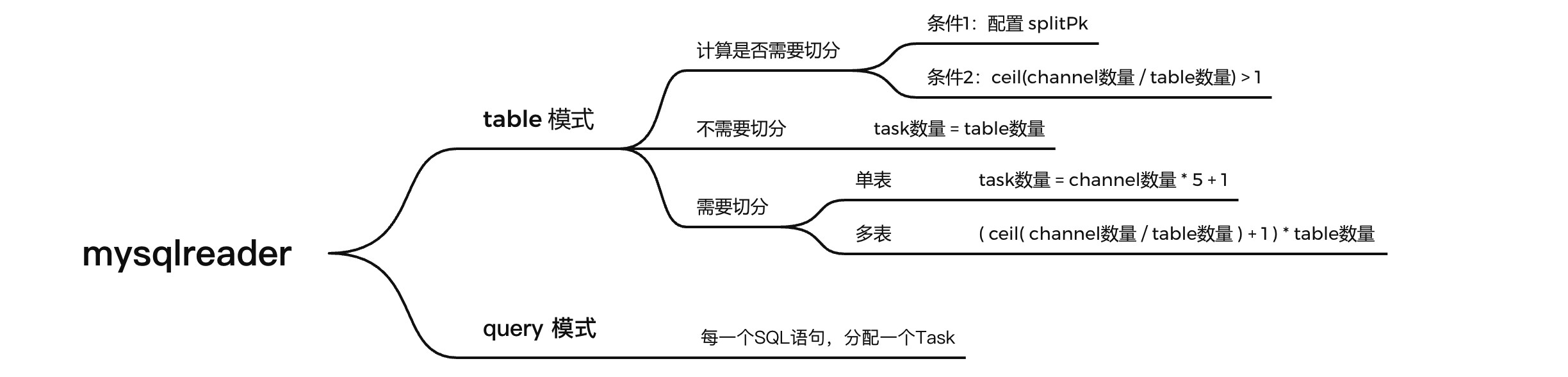
Task划分
mysqlreader读取数据有两种模式:Table模式 和 Query模式
- **Table模式:**connection中设置了table属性,设置了需要同步数据的表。
- **Query模式:**connection中设置了querySql属性,设置了需要同步数据时执行的SQL语句。
这两种模式下,Task的划分机制是不同的。在DataX的源码中有明确的说明
注:DataX的这部分源码是使用Java来编写的,因此下面的源码解析部分是Java的代码。对Java不熟悉的同学可以直接跳过,直接到达最后的总结部分即可。
com.alibaba.datax.plugin.rdbms.reader.CommonRdbmsReader
// 分片的操作
public List<Configuration> split(Configuration originalConfig, int adviceNumber) {
// 使用 ReaderSplitUtil 工具类中的 doSplit 函数来完成具体的分片
// 关键参数:originalConfig 表示mysqlreader设置的parameter信息
// 关键参数:adviceNumber 值为channel的数量
return ReaderSplitUtil.doSplit(originalConfig, adviceNumber);
}
com.alibaba.datax.plugin.rdbms.reader.util.ReaderSplitUtil
// 切分Task的逻辑
// 关键参数:originalConfig 表示mysqlreader设置的parameter信息
// 关键参数 adviceNumber 值为channel的数量
public static List<Configuration> doSplit(Configuration originalSliceConfig, int adviceNumber) {
// 判断是否为 Table 模式(在JSON的connection属性中,如果配置了table,就是Table模式)
boolean isTableMode = originalSliceConfig.getBool(Constant.IS_TABLE_MODE).booleanValue();
// 定义变量,表示每一张表需要切分的数量(只是记录中间的值,并不代表了最终的数量)
int eachTableShouldSplittedNumber = -1;
if (isTableMode) {
// adviceNumber这里是channel数量大小, 即datax并发task数量
// eachTableShouldSplittedNumber是单表应该切分的份数, 向上取整可能和adviceNumber没有比例关系了已经
//
// 这里 calculateEachTableShouldSplittedNumber 的逻辑是:
// double tempNum = 1.0 * adviceNumber / tableNumber;
// return (int) Math.ceil(tempNum);
// 即:计算 channel 数量 / 表的数量
eachTableShouldSplittedNumber = calculateEachTableShouldSplittedNumber(
adviceNumber, originalSliceConfig.getInt(Constant.TABLE_NUMBER_MARK));
}
// 中间省略一大堆...
// 说明是配置的 table 方式
if (isTableMode) {
// 获取到在json的parameter中配置的所有的表
List<String> tables = connConf.getList(Key.TABLE, String.class);
// 获取到在json的parameter中配置的splitPk属性值
String splitPk = originalSliceConfig.getString(Key.SPLIT_PK, null);
// 判断是否需要切分Task
// 判断逻辑:上方计算的 eachTableShouldSplittedNumber > 1 并且设置了splitPk
boolean needSplitTable = eachTableShouldSplittedNumber > 1
&& StringUtils.isNotBlank(splitPk);
if (needSplitTable) {
// 对单表的处理逻辑
if (tables.size() == 1) {
// 获取切分因子,这个切分因子默认是5,可以在json中通过splitFactor设置
Integer splitFactor = originalSliceConfig.getInt(Key.SPLIT_FACTOR, Constant.SPLIT_FACTOR);
// 将上述计算的eachTableShouldSplittedNumber乘5,得到最新的eachTableShouldSplittedNumber
eachTableShouldSplittedNumber = eachTableShouldSplittedNumber * splitFactor;
}
// 尝试对每个表,切分为eachTableShouldSplittedNumber 份
for (String table : tables) {
tempSlice = sliceConfig.clone();
tempSlice.set(Key.TABLE, table);
// 这里调用了splitSingleTable执行每一个Task的具体逻辑
// 包含了:
// 1. 查找 splitPk 字段的最大值、最小值
// 2. 将 [最小值, 最大值] 的区间划分成为eachTableShouldSplittedNumber份
// 3. 每一个Task读取切分之后的一部分数据
// 4. 最后新增一个Task,处理splitPk为NULL的情况
List<Configuration> splittedSlices = SingleTableSplitUtil
.splitSingleTable(tempSlice, eachTableShouldSplittedNumber);
splittedConfigs.addAll(splittedSlices);
}
}
// Table模式、不需要切分
else {
// 遍历所有的表,每个表分配一个Task
for (String table : tables) {
tempSlice = sliceConfig.clone();
tempSlice.set(Key.TABLE, table);
String queryColumn = HintUtil.buildQueryColumn(jdbcUrl, table, column);
tempSlice.set(Key.QUERY_SQL, SingleTableSplitUtil.buildQuerySql(queryColumn, table, where));
splittedConfigs.add(tempSlice);
}
}
} else {
// 说明是配置的 querySql 方式
List<String> sqls = connConf.getList(Key.QUERY_SQL, String.class);
// 每一条SQL,分配一个Task
for (String querySql : sqls) {
tempSlice = sliceConfig.clone();
tempSlice.set(Key.QUERY_SQL, querySql);
splittedConfigs.add(tempSlice);
}
}
}
return splittedConfigs;
}
通过上述代码解读,可以总结出以下结果:
4.3.2. mysqlwriter
介绍
MySQLWriter插件实现了写入数据到MySQL数据库的目的表的功能。在底层实现上,MySQLWriter通过JDBC连接到远程数据库,并执行相应的 insert into ... 或者 replace into ... 的SQL语句,将数据写入到MySQL数据库。内部会分批次提交入库,需要数据库本身采用 innodb 引擎。
MySQLWriter面向ETL开发工程师,他们使用MySQLWriter从数仓导入数据到MySQL。同时MySQLWriter也可以作为数据迁移工具,为DBA等用户提供服务。
实现原理
MySQLWriter通过DataX框架获取Reader生成的协议数据,根据你配置的writeMode生成
- insert: insert into ... (当主键、唯一性索引冲突时会写不进去冲突的行)
- replace: replace into ... (没有遇到主键、唯一性索引冲突时,与insert into行为一致,冲突时会用新行替换原有行的所有字段)
- update: insert into ... on duplicate key update ... (如果 on duplicate key update 的子句中要更新的值与原来的值都一样,则不更新,否则就更新)
生成上述的语句写入数据到MySQL。出于性能考虑,采用了PreparedStatement + Batch,并且设置了rewriteBatchedStatement=true,将数据缓冲到线程上下文Buffer中,当Buffer累计到预定阈值时,才发起写入请求。
注意:
目标表所在数据库必须是主库才能写入数据;整个任务至少需要具备 insert into / replace into 的权限,是否需要其他权限,取决于你任务配置中在preSql和postSql中指定的语句。
参数说明
| 参数 | 描述 | 必选 | 默认值 |
|---|---|---|---|
| jdbcUrl | 目标数据库的JDBC连接信息。作业运行时,DataX会在你提供的jdbcUrl后面追加如下属性: yearIsDateType=false&zeroDateTimeBehavior=convertToNull&rewriteBatchedStatements=true 注意: 1、在一个数据库上只能配置一个jdbcUrl值,这与MySQLReader支持多个备库探测不同,因为此处不支持同一个数据库存在多个主库的情况(双主导入数据情况) 2、jdbcUrl按照MySQL官方规范,并可以填写连接附加控制信息,比如想指定连接编码为gbk,则在jdbcUrl后面追加属性 useUnicode=true&characterEncoding=gbk | 是 | 无 |
| username | 目标数据库的用户名 | 是 | 无 |
| password | 目标数据库的密码 | 是 | 无 |
| table | 目标表的名称,支持写入一个或者多个表。当配置为多张表时,必须确保所有表结构一致。 注意:table和jdbcUrl必须包含在connection配置中。 | 是 | 无 |
| column | 目标表需要写入数据的字段,字段之间用英文逗号分隔。 例如: "column": ["id", "name", "age"] 如果要依次写入全部列,使用*表示,例如: "column": [ "*"] 注意: column配置项必须指定,不能留空 | 是 | 无 |
| preSql | 写入数据到目标表前,会先执行这里的SQL语句。如果SQL中有你需要操作到的表名称,使用@table表示,这样在实际执行SQL语句时,会对变量按照实际表名称进行替换。 | 否 | 无 |
| postSql | 写入数据到目标表后,会执行这里的SQL语句。 | 否 | 无 |
| writeMode | 控制写入数据到目标表采用 insert into、replace into 或者 ON DUPLICATE KEY UPDATE 所有选项: insert / replace / update | 否 | insert |
| batchSize | 一次性批量提交的记录数大小,这个值可以极大的减少DataX与MySQL的网络交互次数,并提升整体吞吐量。但是该值设置过大可能会造成DataX运行进行OOM情况。 | 否 | 1024 |
类型转换
下面是MySQLWriter与MySQL数据类型转换的对比表
| DataX内部类型 | MySQL数据类型 |
|---|---|
| Long | int, tinyint, smallint, mediumint, int, bigint, year |
| Double | float, double, decimal |
| String | varchar, char, tinytext, text, mediumtext, longtext |
| Date | date, datetime, timestamp, time |
| Boolean | bit, bool |
| Bytes | tinyblob, mediumblob, blob, longblob, varbinary |
配置样例1
这里使用一份从内存的数据,导出到MySQL中。
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column": [
{"value": "9870", "type": "long" },
{"value": "SHAWN", "type": "string"},
{"value": "BOSS", "type": "string"},
{"value": "1999-01-01", "type": "string"},
{"value": "99999", "type": "long"}
],
"sliceRecordCount": 10
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "root",
"password": "123456",
"column": ["empno", "ename", "job", "hiredate", "sal"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://qianfeng01:3306/mydb",
"table": ["emp"]
}
]
}
}
}
]
}
}
配置样例2
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column": [
{"value": "9870", "type": "long" },
{"value": "SHAWN", "type": "string"},
{"value": "BOSS", "type": "string"},
{"value": "1999-01-01", "type": "string"},
{"value": "99999", "type": "long"}
],
"sliceRecordCount": 10
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "replace",
"username": "root",
"password": "123456",
"column": ["empno", "ename", "job", "hiredate", "sal"],
"preSql": ["delete from emp"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://qianfeng01:3306/mydb",
"table": ["emp"]
}
]
}
}
}
]
}
}
4.4. HDFS
4.4.1. hdfsreader
介绍
HDFSReader提供了读取分布式文件系统数据存储的能力。在底层实现上,HDFSReader获取分布式文件系统上文件的数据,并转换为DataX传输协议传递给Writer。
- 支持 textfile、orcfile、rcfile、sequence file、csv 格式的文件,且文件的内容必须是一张逻辑意义上的二维表。
- 支持多种类型数据读取(使用String表示),支持列裁剪,支持列常量。
- 支持递归读取,支持正则表达式(* 和 ?)。
- 支持orcfile数据压缩,目前支持SNAPPY、ZLIB两种压缩方式。
- 多个File可以支持并发读取。
- 支持sequence file数据压缩,目前支持lzo压缩方式。
- csv类型支持压缩格式有: gzip、bz2、zip、lzo、lzo_deflate、snappy。
- 支持kerberos认证。
参数说明
| 参数 | 描述 | 必选 | 默认值 |
|---|---|---|---|
| path | 需要读取的HDFS文件的路径,如果需要读取多个文件,可以使用*通配。 需要注意: DataX会将一个作业下同步的所有文件视为同一张数据表,所以必须要保证所有的文件能够适配同一套schema信息。 | 是 | 无 |
| defaultFS | HDFS文件系统的namenode地址。 目前HDFSReader支持Kerberos认证,如果需要权限认证,则需要用户配置Kerberos参数。 | 是 | 无 |
| fileType | 文件的类型,目前只支持配置为: text、orc、rc、seq、csv | 是 | 无 |
| column | 读取字段列表,type指定源数据的类型,index指定当前列来自于文本第几列(从0开始),value指定当前类型为常量,不从源头文件读取数据,而是根据value值自动生成对应的列。 默认情况下,用户可以按照string类型读取数据, "column": ["*"] | 是 | 全部按照string读取 |
| fieldDelimiter | 读取的字段分隔符 读取orcfile的时候,无需指定字段分隔符 | 否 | , |
| encoding | 读取文件的编码。 | 否 | Utf-8 |
| nullFormat | 文本文件中无法使用标准字符串定义null,DataX提供nullFormat定义哪些字符串可以表示为null。例如如果配置 nullFormat: "\N",则文本中的数据是 \N 的时候,DataX会视为null。 | 否 | 无 |
| haveKerberos | 是否有Kerberos认证。 如果配置为true,则需要配置kerberosKeytabFilePath, kerberosPrincipal | 否 | false |
| kerberosKeytabFilePath | Kerberos认证keytab文件路径,绝对路径 | 否 | 无 |
| kerberosPrincipal | Kerberos认证Principal名 | 否 | 无 |
| compress | 当fileType为csv时,文件压缩的方式,目前支持: gzip、bz2、zip、lzo、lzo_defalte、hadoop-snappy、framing-snappy | 否 | 无 |
| hadoopConfig | 配置Hadoop相关的一些高级参数,例如HA的配置。 | 否 | 无 |
| csvReaderConfig | 读取csv类型文件参数配置,Map类型。 | 否 | 无 |
hadoopConfig相关配置
"hadoopConfig":{ "dfs.nameservices": "testDfs", "dfs.ha.namenodes.testDfs": "namenode1,namenode2", "dfs.namenode.rpc-address.aliDfs.namenode1": "", "dfs.namenode.rpc-address.aliDfs.namenode2": "", "dfs.client.failover.proxy.provider.testDfs": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider" }csvReader常见配置
"csvReaderConfig":{ "safetySwitch": false, "skipEmptyRecords": false, "useTextQualifier": false }csvReader所有配置项
boolean caseSensitive = true; char textQualifier = 34; boolean trimWhitespace = true; boolean useTextQualifier = true;//是否使用csv转义字符 char delimiter = 44;//分隔符 char recordDelimiter = 0; char comment = 35; boolean useComments = false; int escapeMode = 1; boolean safetySwitch = true;//单列长度是否限制100000字符 boolean skipEmptyRecords = true;//是否跳过空行 boolean captureRawRecord = true;
类型转换
- Long 指Hdfs文件文本中使用整形的字符串表示形式,例如"123456789"。
- Double 指Hdfs文件文本中使用Double的字符串表示形式,例如"3.1415"。
- Boolean 指Hdfs文件文本中使用Boolean的字符串表示形式,例如"true"、"false"。不区分大小写。
- Date 指Hdfs文件文本中使用Date的字符串表示形式,例如"2014-12-31"。
配置样例1
读取HDFS的文件并输出到控制台
{
"job": {
"setting": {
"speed": {
"channel": 3
}
},
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"path": "/emp.txt",
"defaultFS": "hdfs://qianfeng01:9820",
"column": [ "*" ],
"fileType": "text"
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print": true
}
}
}
]
}
}
配置样例2
读取HDFS指定列的数据到控制台
{
"job": {
"setting": {
"speed": {
"channel": 3
}
},
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"path": "/emp.txt",
"defaultFS": "hdfs://qianfeng01:9820",
"column": [
{"index": 0, "type": "long"},
{"index": 1, "type": "string"},
{"index": 5, "type": "double"},
{"value": "HAHAHA", "type": "string"}
],
"fileType": "text",
"encoding": "UTF-8",
"filedDelimiter": ","
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print": true
}
}
}
]
}
}
4.4.2. hdfswriter
介绍
HDFSWriter可以向HDFS文件系统的指定路径中写入 TextFile 或者 orcFile 文件,文件内容可以直接与Hive关联。
-
目前HDFSWriter仅支持textfile和orcfile两种格式的文件,且文件内容存放的必须是一张逻辑意义上的二维表。
-
由于HDFS是文件系统,不存在schema的概念,因此不支持对部分列的写入。
-
目前仅支持以下数据类型:
数值型: TINYINT, SMALLINT, INT, BIGINT, FLOAT, DOUBLE 字符串类型: STRING, VARCHAR, CHAR 布尔型: BOOLEAN 时间类型: DATE, TIMESTAMP 注意: 暂不支持 deimal, binary, arrays, maps, structs, union 类型 -
对于Hive分区表,目前仅支持一次写入一个分区。
-
对于textfile需要用户保证写入HDFS文件的分隔符与在Hive表上创建表时的分隔符一致,从而实现写入HDFS数据与Hive表字段关联。
-
HDFSWriter实现过程:
- 根据用户指定的path,创建一个HDFS文件系统上不存在的临时目录
- 将读取的文件写入这个临时目录
- 全部写入后,再将这个临时目录下的文件移动到用户指定的目录
- 最后删除这个临时目录
- 如果再中间过程发生网络中断等情况,造成无法与HDFS建立连接,需要用户手动删除已经写入的文件和临时目录。
参数说明
| 参数 | 描述 | 必选 | 默认值 |
|---|---|---|---|
| defaultFS | HDFS文件系统的namenode节点地址。 | 是 | 无 |
| fileType | 文件的类型,目前只支持用户配置为text或者orc。 | 是 | 无 |
| path | 存储到HDFS文件系统的路径信息,HDFSWriter会根据并发配置在Path目录下写入多个文件。 如果需要与Hive表关联,需要填写Hive表在HDFS上的存储路径。 这个路径需要存在。 | 是 | 无 |
| fileName | HDFSWriter写入时的文件名,实际执行时会在该文件名后添加随机的后缀作为每个线程写入实际文件名。 | 是 | 无 |
| column | 写入数据的字段,不支持对部分列写入。为与Hive中表关联,需要指定表中所有字段名和字段类型,其中name指定字段名,type指定字段类型。 | 是 | 无 |
| writeMode | HDFSWriter写入前数据清理处理模式: append: 写入前不做任何处理,DataX HDFSWriter直接使用filename写入,并保证文件名不冲突。 nonConflict: 如果目录下有fileName前缀的文件,直接报错。 | 是 | 无 |
| filedDelimiter | HDFSWriter写入时的字段分隔符,需要用户保证与创建的Hive表的字段分隔符一致,否则无法在Hive表中查到数据。 | 是 | 无 |
| compress | HDFS文件压缩类型,默认不填写意味着没有压缩。 text类型文件支持压缩类型有: gzip, bzip2 orc类型文件支持压缩类型有: NONE, SNAPPY(需要用户安装SnappyCodec) | 否 | 无 |
| hadoopConfig | 配置Hadoop相关的一些高级参数,比如HA的配置。 | 否 | 无 |
| encoding | 写文件的编码配置。 | 否 | Utf-8 |
| haveKerberos | 是否有Kerberos认证,默认值false 例如如果用户配置true,则配置项kerberosKeytabFilePath, kerberosPrincipal必需要配置 | 否 | false |
| kerberosKeytabFilePath | Kerberos认证keytab文件路径,绝对路径 | 否 | 无 |
| kerberosPrincipal | Kerberos认证Principal名 | 否 | 无 |
配置样例1
{
"job": {
"setting": {
"speed": {
"channel": 3
}
},
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column": [
{"value": "9870", "type": "long" },
{"value": "SHAWN", "type": "string"},
{"value": "BOSS", "type": "string"},
{"value": "1999-01-01", "type": "string"},
{"value": "99999", "type": "long"}
],
"sliceRecordCount": 10
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://qianfeng01:9820",
"path": "/datax/emp",
"fileName": "emp",
"column": [
{"name": "empno", "type": "string"},
{"name": "ename", "type": "string"},
{"name": "job", "type": "string"},
{"name": "hiredate", "type": "string"},
{"name": "sal", "type": "double"}
],
"fileType": "text",
"writeMode": "append",
"fieldDelimiter": ","
}
}
}
]
}
}
配置样例2
{
"job": {
"setting": {
"speed": {
"channel": 3
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123456",
"connection": [
{
"table": ["emp"],
"jdbcUrl": ["jdbc:mysql://qianfeng01:3306/mydb"]
}
],
"column": ["*"],
"splitPk": "empno"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://qianfeng01:9820",
"path": "/datax/mydb/emp",
"fileName": "emp",
"column": [
{"name": "empno", "type": "int"},
{"name": "ename", "type": "string"},
{"name": "job", "type": "string"},
{"name": "mgr", "type": "int"},
{"name": "hiredate", "type": "string"},
{"name": "sal", "type": "double"},
{"name": "comm", "type": "double"},
{"name": "deptno", "type": "long"}
],
"fileType": "text",
"writeMode": "append",
"fieldDelimiter": ","
}
}
}
]
}
}
4.5. Hive
4.5.1. hivereader
介绍
DataX并没有hivereader这个插件,因为Hive的数据都是存储于HDFS之上的,因此读取Hive的数据需要通过hdfsreader来实现。在读取Hive的表数据的时候,需要设置path为数据存储的目录即可。
配置样例1
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"defaultFS": "hdfs://qianfeng01:9820",
"path": "/user/hive/warehouse/my_db1.db/emp/*",
"column": ["*"],
"fieldDelimiter": ",",
"fileType": "text"
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print": true
}
}
}
]
}
}
配置样例2
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"defaultFS": "hdfs://qianfeng01:9820",
"path": "/user/hive/warehouse/my_db1.db/emp/*",
"column": ["*"],
"fieldDelimiter": ",",
"fileType": "text",
"nullFormat": "null"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"username": "root",
"password": "123456",
"connection": [
{
"jdbcUrl": "jdbc:mysql://qianfeng01:3306/mydb",
"table": ["emp2"]
}
],
"column": ["*"],
"preSql": ["delete from @table"]
}
}
}
]
}
}
4.5.2. hivewriter
介绍
DataX并没有hivewriter这个插件,因为Hive的数据都是存储于HDFS之上的,因此写数据到Hive其实本质就是将数据写入到HDFS的指定目录下的,因此使用hivewriter这个插件即可。在写数据的时候,需要设置path为表数据存储的目录即可。
配置样例1
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column": [
{"value": "8888", "type": "string"},
{"value": "SHAWN", "type": "string"},
{"value": "PROGRAMMER", "type": "string"},
{"value": "null", "type": "string"},
{"value": "2000-01-01", "type": "string"},
{"value": "9999", "type": "string"},
{"value": "1000", "type": "string"},
{"value": "20", "type": "string"}
],
"sliceRecordCount": 1
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://qianfeng01:9820",
"path": "/user/hive/warehouse/my_db1.db/emp/",
"fileName": "datax",
"column": [
{"name": "empno", type: "string"},
{"name": "ename", type: "string"},
{"name": "job", type: "string"},
{"name": "mgr", type: "string"},
{"name": "hiredate", type: "string"},
{"name": "sal", type: "string"},
{"name": "comm", type: "string"},
{"name": "deptno", type: "string"}
],
"writeMode": "append",
"fieldDelimiter": ",",
"fileType": "text"
}
}
}
]
}
}
配置样例2
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123456",
"connection": [
{
"jdbcUrl": ["jdbc:mysql://qianfeng01:3306/mydb"],
"table": ["emp"]
}
],
"column": ["*"],
"where": "mgr is not null"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://qianfeng01:9820",
"path": "/user/hive/warehouse/my_db1.db/emp2/",
"fileName": "datax",
"column": [
{"name": "empno", type: "string"},
{"name": "ename", type: "string"},
{"name": "job", type: "string"},
{"name": "mgr", type: "string"},
{"name": "hiredate", type: "string"},
{"name": "sal", type: "string"},
{"name": "comm", type: "string"},
{"name": "deptno", type: "string"}
],
"writeMode": "append",
"fieldDelimiter": ",",
"fileType": "text"
}
}
}
]
}
}
第五章 实战案例
5.1. 案例一
5.1.1. 案例介绍
MySQL数据库中有两张表:用户表(users),订单表(orders)。其中用户表中存储的是所有的用户的信息,订单表中存储的是所有的订单的信息。表结构如下:
-
用户表 users:
-
id:用户id
-
username:用户名
-
password:用户密码
-
email:用户邮箱
-
phone:用户手机号码
-
real_name:用户的真实姓名
-
registration_time:用户的注册时间
-
last_login_time:用户的上次登录时间
-
status:用户的状态(活跃、不活跃、冻结)
-
-
订单表 orders:
- id:订单ID
- user_id:用户ID
- seller_id:卖家ID
- product_id:商品ID
- product_name:商品名称
- product_price:商品单价
- quantity:购买数量
- total_price:订单总价
- order_time:订单时间
业务系统中,每天都有新的用户注册,每天也都在产生大量的订单。今天公司刚刚搭建了数据仓库,需要将已有的数据导入到Hive表中,此时需要将已有的数据全量的导入到Hive的表中。后续每天产生的新用户注册和新的订单,增量的导入到对应的Hive表中。
5.1.2. 数据准备
MySQL中初始数据
# 创建数据库
CREATE DATABASE datax_shop;
USE datax_shop;
# 创建用户表
DROP TABLE IF EXISTS users;
CREATE TABLE users (
id INT(11) UNSIGNED NOT NULL AUTO_INCREMENT,
username VARCHAR(50) NOT NULL,
password VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL,
phone VARCHAR(20) NOT NULL,
real_name VARCHAR(50) NOT NULL,
registration_time DATE NOT NULL,
last_login_time DATE NULL DEFAULT NULL,
status ENUM('active', 'inactive', 'frozen') NOT NULL DEFAULT 'active',
PRIMARY KEY (id),
UNIQUE KEY (username),
UNIQUE KEY (email),
UNIQUE KEY (phone)
);
# 插入一些数据
INSERT INTO users (username, password, email, phone, real_name, registration_time, last_login_time) VALUES
('johndoe','123456','johndoe@163.com','17767827612','John Doe','2020-12-12','2022-09-12'),
('janedoe','123123','janedoe@qq.com','18922783392','Jane Doe','2021-02-12','2022-12-10'),
('bobsmith','121212','bobsmith@126.com','17122811292','Bob Smith','2020-10-11','2022-01-15'),
('sarahlee','11111','sarahlee@qq.com','17122810911','Sarah Lee','2019-03-15','2022-02-15'),
('jimmychang','123121','jimmychang@qq.com','155514442134','Jimmy Chang','2022-12-11', NULL),
('alexjohnson','121212','alexjohnson@126.com','15522427212','Alex Johnson','2021-09-01', NULL);
# 创建订单表
DROP TABLE IF EXISTS orders;
CREATE TABLE orders (
id INT PRIMARY KEY AUTO_INCREMENT,
user_id INT NOT NULL,
seller_id INT NOT NULL,
product_id INT NOT NULL,
product_name VARCHAR(255) NOT NULL,
product_price DECIMAL(10, 2) NOT NULL,
quantity INT NOT NULL,
total_price DECIMAL(10, 2) NOT NULL,
order_time DATE NOT NULL
);
# 插入一些数据
INSERT INTO orders (user_id, seller_id, product_id, product_name, product_price, quantity, total_price, order_time) VALUES
(1, 1, 12, '电动牙刷', 90, 1, 90, '2020-12-20'),
(1, 2, 15, '洗面奶', 45, 1, 45, '2020-12-20'),
(1, 3, 17, '面膜', 110, 2, 220, '2020-12-20'),
(2, 1, 11, 'iPad', 5990, 1, 5990, '2021-12-20'),
(2, 2, 19, 'iPhone数据线', 18, 1, 18, '2021-11-20'),
(3, 1, 20, 'iPhone手机壳', 80, 1, 80, '2020-12-20'),
(3, 2, 22, '榴莲', 45, 4, 180, '2021-09-12'),
(3, 3, 23, '西瓜', 12, 5, 60, '2021-11-11'),
(4, 1, 4, '洗地机', 2990, 1, 2990, '2020-06-18'),
(4, 2, 7, '油污清洁剂', 78, 2, 156, '2020-07-11'),
(4, 3, 11, '镜子', 10, 1, 10, '2020-06-20'),
(5, 1, 9, '健力宝', 48, 2, 96, '2022-12-20');
Hive表的创建
-- 创建数据库
create database datax_shop;
-- 创建用户表
drop table if exists datax_shop.users;
create table datax_shop.users (
id int,
username string,
password string,
email string,
phone string,
real_name string,
registration_time string,
last_login_time string,
status string
)
row format delimited
fields terminated by '\t'
lines terminated by '\n'
stored as orcfile;
-- 创建订单表
drop table if exists datax_shop.orders;
create table datax_shop.orders (
id int,
user_id int,
seller_id int,
product_id int,
product_name string,
product_price double,
quantity int,
total_price double,
order_time string
)
partitioned by (year string, month string)
row format delimited
fields terminated by '\t'
lines terminated by '\n'
stored as orcfile;
5.1.3. 数据全量导入
用户表全量导入
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123456",
"column": [
"id",
"username",
"password",
"email",
"phone",
"real_name",
"registration_time",
"last_login_time",
"status"
],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://qianfeng01:3306/datax_shop"],
"table": ["users"]
}
]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://qianfeng01:9820",
"path": "/user/hive/warehouse/datax_shop.db/users",
"fileName": "original",
"writeMode": "append",
"fieldDelimiter": "\t",
"fileType": "orc",
"column": [
{"name": "id", "type": "int"},
{"name": "username", "type": "string"},
{"name": "password", "type": "string"},
{"name": "email", "type": "string"},
{"name": "phone", "type": "string"},
{"name": "real_name", "type": "string"},
{"name": "registration_time", "type": "string"},
{"name": "last_login_time", "type": "string"},
{"name": "status", "type": "string"}
]
}
}
}
]
}
}
订单表全量导入
订单表在全量导入的时候,因为要按照订单创建时候的日期作为分区的字段。所以需要创建一张临时表,先将MySQL中的订单数据全量的导入到这个临时表中,然后再从这个临时表加载到订单表的指定分区中。
-- 创建临时表,用来承接全量导入的订单信息
drop table if exists datax_shop.orders_origin;
create table datax_shop.orders_origin (
id int,
user_id int,
seller_id int,
product_id int,
product_name string,
product_price double,
quantity int,
total_price double,
order_time string,
year string,
month string
)
row format delimited
fields terminated by '\t'
lines terminated by '\n';
创建数据同步方案,同步MySQL的订单数据到这个临时表中
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123456",
"connection": [
{
"jdbcUrl": ["jdbc:mysql://qianfeng01:3306/datax_shop"],
"table": ["orders"]
}
],
"column": [
"id",
"user_id",
"seller_id",
"product_id",
"product_name",
"product_price",
"quantity",
"total_price",
"order_time",
"year(order_time)",
"lpad(month(order_time), 2, 0)"
]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://qianfeng01:9820",
"path": "/user/hive/warehouse/datax_shop.db/orders_origin/",
"fileName": "orders_origin",
"writeMode": "append",
"fieldDelimiter": "\t",
"fileType": "text",
"column": [
{"name": "id", "type": "int"},
{"name": "user_id", "type": "int"},
{"name": "seller_id", "type": "int"},
{"name": "product_id", "type": "int"},
{"name": "product_name", "type": "string"},
{"name": "product_price", "type": "double"},
{"name": "quantity", "type": "double"},
{"name": "total_price", "type": "double"},
{"name": "order_time", "type": "string"},
{"name": "year", "type": "string"},
{"name": "month", "type": "string"}
]
}
}
}
]
}
}
加载数据,到orders表的对应分区中
-- 关闭严格模式
set hive.exec.dynamic.partition.mode=nonstrict;
-- 导入数据到订单表中
insert into datax_shop.orders partition(year, month) select * from datax_shop.orders_origin;
5.1.4. 增量数据导入
用户表增量导入
在现有数据全量导入到Hive表中之后,每日新增的数据只需要增量导入到Hive即可。此时我们就可以按照用户注册的时间来确定需要将什么数据导入到Hive的用户表中。
首先,我们在将现有的数据全量的导入到Hive之后,模拟新用户的注册。
INSERT INTO users (username, password, email, phone, real_name, registration_time, last_login_time) VALUES
('natalielin','121212','natalielin@qq.com','17788889999','Natalie Lin','2023-01-01', NULL),
('harrytran','123123','harrytran@126.com','17666228192','Harry Tran','2023-01-01', NULL),
('gracewang','313131','gracewang@163.com','18872631272','Grace Wang','2023-01-01', NULL),
('peterlee','123123','peterlee@qq.com','19822781829','Peter Lee','2023-01-01',NULL);
现在我们需要将在 2023-01-01 注册的用户,增量导入到Hive的用户表中。
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123456",
"column": [
"id",
"username",
"password",
"email",
"phone",
"real_name",
"registration_time",
"last_login_time",
"status"
],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://qianfeng01:3306/datax_shop"],
"table": ["users"]
}
],
"where": "registration_time = '$date'"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://qianfeng01:9820",
"path": "/user/hive/warehouse/datax_shop.db/users",
"fileName": "append",
"writeMode": "append",
"fieldDelimiter": "\t",
"fileType": "orc",
"column": [
{"name": "id", "type": "int"},
{"name": "username", "type": "string"},
{"name": "password", "type": "string"},
{"name": "email", "type": "string"},
{"name": "phone", "type": "string"},
{"name": "real_name", "type": "string"},
{"name": "registration_time", "type": "string"},
{"name": "last_login_time", "type": "string"},
{"name": "status", "type": "string"}
]
}
}
}
]
}
}
在上述的数据同步的方案中,我们使用到了变量 date 用来表示需要增量导入用户的注册时间。在使用这个数据同步方案的时候,需要指定变量 date 的值:
python3 /usr/local/datax/bin/datax.py -p "-Ddate=2023-01-01" incr-users.json
订单表增量导入
在现有的所有订单数据全量导入到Hive的订单表后,每天仍然会有大量的订单数据生成。此时我们只需要按照天为单位,将某一天产生的所有的数据增量导入到Hive的订单表中,并放置在指定的分区位置即可。
首先,在现有的订单数据全量导入到Hive的订单表之后,我们来模拟一些新增的订单信息
INSERT INTO orders (user_id, seller_id, product_id, product_name, product_price, quantity, total_price, order_time) VALUES
(6, 1, 110, '大米', 90, 1, 90, '2023-01-01'),
(6, 2, 120, '护手霜', 20, 2, 40, '2023-01-01'),
(6, 3, 130, '地板', 120, 5, 600, '2023-01-01'),
(7, 1, 140, '筒灯', 100, 10, 1000, '2023-01-01'),
(7, 2, 150, '假发', 2000, 1, 2000, '2023-01-01'),
(7, 3, 160, '牛奶', 100, 2, 200, '2023-01-01'),
(8, 1, 170, '百褶裙', 1000, 2, 2000, '2023-01-01'),
(8, 2, 180, '真丝丝巾', 300, 2, 600, '2023-01-01'),
(8, 3, 190, '太阳镜', 250, 1, 250, '2023-01-01'),
(9, 1, 200, '遮阳伞', 120, 1, 120, '2023-01-01'),
(9, 2, 210, '盆栽', 220, 5, 1100, '2023-01-01'),
(10, 1, 220, '口琴', 50, 1, 50, '2023-01-01'),
(10, 2, 230, 'RIO', 12, 10, 120, '2023-01-01');
现在我们需要将某一天的数据增量的导入到Hive对应的分区中,其实这个过程就是使用hdfswriter将增量的数据直接写入到HDFS的指定分区目录下即可。但是需要保证这个分区已经被创建出来了。
-- 检查指定分区是否存在
show partitions datax_shop.orders partition(year='2023', month='01');
-- 如果这个分区不存在,就创建这个分区
alter table datax_shop.orders add partition(year='2023', month='01');
分区创建完成之后,就可以将某天新增的数据同步到对应的分区目录了
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123456",
"column": [
"id",
"user_id",
"seller_id",
"product_id",
"product_name",
"product_price",
"quantity",
"total_price",
"order_time"
],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://qianfeng01:3306/datax_shop"],
"table": ["orders"]
}
],
"where": "order_time = '$date'"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://qianfeng01:9820",
"path": "/user/hive/warehouse/datax_shop.db/orders/year=$year/month=$month",
"fileName": "append",
"writeMode": "append",
"fieldDelimiter": "\t",
"fileType": "orc",
"column": [
{"name": "id", "type": "int"},
{"name": "user_id", "type": "int"},
{"name": "seller_id", "type": "int"},
{"name": "product_id", "type": "int"},
{"name": "product_name", "type": "string"},
{"name": "product_price", "type": "double"},
{"name": "quantity", "type": "double"},
{"name": "total_price", "type": "double"},
{"name": "order_time", "type": "string"}
]
}
}
}
]
}
}
在上述的数据同步方案中,我们定义了三个变量:date、year、month,用来控制从MySQL数据库导入的数据和存放到Hive的对应的分区。因此我们在使用这个配置同步数据的时候,需要指定这三个变量值:
python3 /usr/local/datax/bin/datax.py -p "-Ddate=2023-01-01 -Dyear=2023 -Dmonth=01" incr-orders.json
5.1.5. 脚本调度
我们已经实现了将指定日期(2023-01-01)的增量的数据导入到Hive对应的数据表中,但是这样做不够灵活,我们不能每一次在需要增量导入的时候都去执行上述的一个个命令。为了能够更加方便的同步数据,以及可以定时的进行调度,我们可以将其做成一个脚本,在需要的时候直接调用即可。
shell脚本
#!/bin/bash
# 获取需要同步的数据的日期为昨天
# dt=`date -d yesterday +"%Y-%m-%d"`
dt='2023-01-01'
# 提取年
year=${dt:0:4}
month=${dt:5:2}
# 设置DataX路径
DATAX_HOME=/usr/local/datax
# 设置jobs路径
JOBS_HOME=/root/datax-example
# 增量导入用户数据
python $DATAX_HOME/bin/datax.py -p "-Ddate=$dt" $JOBS_HOME/incr-users.json
# 增量导入订单数据
# 1. 检查Hive表目标分区是否存在,如果目标分区不存在,创建分区
if [ ! hive -e "show partitions datax_shop.orders partition(year='$year', month='$month')" ]; then
hive -e "alter table datax_shop.orders add partition(year='$year', month='$month')"
fi
# 3. 执行增量导入订单
python $DATAX_HOME/bin/datax.py -p "-Ddate=$dt -Dyear=$year -Dmonth=$month" $JOBS_HOME/incr-orders.json
python脚本
# @Author : 千锋大数据教研院
# @Company : 北京千锋互联科技有限公司
import datetime
import os
from pyhive import hive
# 在脚本中需要和Hive进行交互,查询Hive表的分区是否存在、创建分区等操作,因此需要使用到PyHive
# 如果没有安装的话,需要手动安装一下PyHive
# yum install cyrus-sasl-plain cyrus-sasl-devel cyrus-sasl-gssapi
# pip3 install thrift
# pip3 install sasl
# pip3 install thrift-sasl
# pip3 install pyhive
# PyHive需要使用Hive的ThriftServer服务,因此需要保证你的Hive对应的服务是打开的
# nohup hive --service hiveserver2 > /var/log/hiveserver2 2>&1 &
# 设置 DataX 和 Jobs 的Home路径
DATAX_HOME = "/usr/local/datax"
JOBS_HOME = "/root/datax-example"
# 设置同步任务的JSON配置文件名
INCR_USERS = "incr-users.json"
INCR_ORDERS = "incr-orders.json"
# 获取当前时间
# now = datetime.datetime(2023, 1, 1)
now = datetime.datetime.now()
dt = str(now.date())
year = f"{now.year:0>4}"
month = f"{now.month:0>2}"
# 增量导入用户数据
os.system(f'python {DATAX_HOME}/bin/datax.py -p "-Ddate={dt}" {JOBS_HOME}/{INCR_USERS}')
# 查看Hive的指定分区是否存在,如果不存在,创建分区
with hive.Connection(host="192.168.10.111", port=10000, username="root", database="datax_shop") as conn:
with conn.cursor() as cursor:
cursor.execute(f"show partitions orders partition(year='{year}', month='{month}')")
partitions = cursor.fetchone()
if partitions is None:
# 说明这个分区不存在,创建
cursor.execute(f"alter table orders add partition(year='{year}', month='{month}')")
# 增量导入订单数据
os.system(f'python {DATAX_HOME}/bin/datax.py -p "-Ddate={dt} -Dyear={year} -Dmonth={month}" {JOBS_HOME}/{INCR_ORDERS}')
第六章 DataX-Web
6.1. datax-web介绍
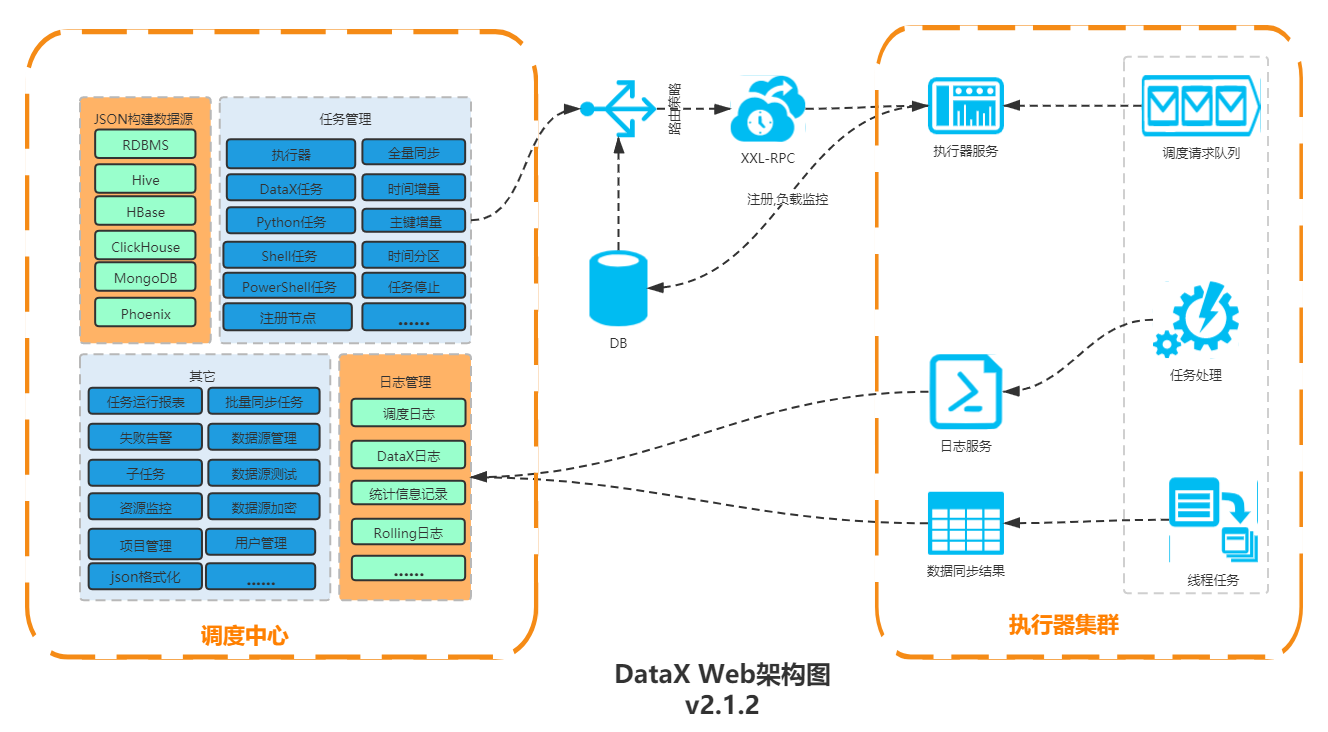
6.1.1. datax-web是什么
datax-web是一个在DataX之上开发的分布式数据同步工具,提供简单易用的操作界面,降低用户使用DataX的学习成本,缩短任务配置时间,避免配置过程中出错。用户可以通过页面选择数据源,即可创建数据同步任务。支持RDBMS、Hive、HBase、ClickHouse、MongoDB等数据源。RDBMS数据源可以批量创建数据同步任务,支持实时查看数据同步进度及日志,并提供终止同步功能,集成并二次开发xxl-job,可根据时间、自增主键增量同步数据。
任务“执行器”支持集群部署,支持执行器多节点路由策略选择,支持超时控制、失败重试、失败告警、任务依赖,执行器CPU、内存、负载的监控等等。
6.1.2. datax-web架构
6.2. datax-web安装部署
6.2.1. 环境要求
| 环境 | 要求 |
|---|---|
| 操作系统 | mac、Windows、Linux |
| Java | Java8,jdk的版本建议在1.8.201以上 |
| Python | 如果没有替换DataX的bin目录下的Python文件:Python 2.7 如果替换了DataX的bin目录下的Python文件:Python 3 |
| MySQL | MySQL 5.7+ |
| Maven | Apache Maven 3.6.1+,编译安装包需要 |
| DataX | DataX 3 |
6.2.2. 安装
二进制安装
直接将安装包下载下来,解压安装到指定的路径即可
tar -zxvf datax-web-2.1.2.tar.gz -C /usr/local
编译打包
目的是为了编译生成安装包文件
- 将
datax-web解压到任意目录下,并使用cd命令进入到这个目录。 - 使用
mvn clean install使用Maven下载依赖的包,并编译打包文件。 - 完成之后,将会在源码包的
build目录下生成datax-web-2.1.2.tar.gz文件。 - 解压到
/usr/local目录下。
6.2.3. 部署
解压安装包
解压 data-web 的安装包,如果上面已经解压过了,跳过
tar -zxvf datax-web-2.1.2.tar.gz -C /usr/local
执行一键安装的脚本
进入解压后的目录,找到 bin 目录下面的 install.sh 文件,如果选择交互式的安装,则直接执行
./bin/install.sh
在交互式安装模式下,将会对各个模块的package压缩包进行解压以及configure配置脚本的使用,都会请求用户确认,可以根据提示查看是否安装成功,如果没有安装成功,可以重复尝试。
如果不想使用交互模式,跳过确认的过程,可以执行下面的命令进行安装
./bin/install.sh --force
元数据库初始化
datax-web需要将一些元数据信息保存到数据库中,在安装的时候,如果你的服务器上安装有 mysql 命令,在执行脚本安装的过程中,会有重要的提醒:
Scan out mysql command, so begin to initalize the database
Do you want to initalize database with sql: [{INSTALL_PATH}/bin/db/datax-web.sql]? (Y/N)y
Please input the db host(default: 127.0.0.1):
Please input the db port(default: 3306):
Please input the db username(default: root):
Please input the db password(default: ):
Please input the db name(default: exchangis)
安装输入提示数据库地址、端口号、用户名、密码以及数据库名称,大部分情况下即可快速完成初始化。如果服务器上并没有mysql命令,则可以使用 $DATAX_HOME/bin/datax-web.sql 脚本去手动执行,完成后修改相关配置文件即可。
vim /usr/local/datax-web/modules/datax-admin/conf/boopstrap.properties
#Database
#DB_HOST=
#DB_PORT=
#DB_USERNAME=
#DB_PASSWORD=
#DB_DATABASE=
配置
安装完成之后,在项目目录: /modules/datax-admin/bin/env.properties 配置邮件服务(可跳过)
MAIL_USERNAME=""
MAIL_PASSWORD=""
此文件中包括一些默认配置参数,例如:server.port,具体请查看文件。
在项目目录下 /modules/datax-execute/bin/env.properties 指定PYTHON_PATH的路径
vi ./modules/{module_name}/bin/env.properties
### 执行datax的python脚本地址
PYTHON_PATH=
### 保持和datax-admin服务的端口一致;默认是9527,如果没改datax-admin的端口,可以忽略
DATAX_ADMIN_PORT=
此文件中包括一些默认配置参数,例如:executor.port,json.path,data.path等,具体请查看文件。
启动
一键启动所有服务
./bin/start-all.sh
中途可能发生部分模块启动失败或者卡住,可以退出重复执行,如果需要改变某一模块服务端口号,则:
vi ./modules/{module_name}/bin/env.properties
找到SERVER_PORT配置项,改变它的值即可。 当然也可以单一地启动某一模块服务:
./bin/start.sh -m {module_name}
一键取消所有服务
./bin/stop-all.sh
当然也可以单一地停止某一模块服务:
./bin/stop.sh -m {module_name}
查看
在Linux环境下使用JPS命令,查看是否出现DataXAdminApplication和DataXExecutorApplication进程,如果存在这表示项目运行成功
如果项目启动失败,请检查启动日志:modules/datax-admin/bin/console.out或者modules/datax-executor/bin/console.out
WebUI
部署完成后,在浏览器中输入 http://ip:9527/index.html 就可以访问对应的主界面(ip为datax-admin部署所在服务器ip,port为为datax-admin 指定的运行端口)
输入用户名 admin 密码 123456 就可以直接访问系统
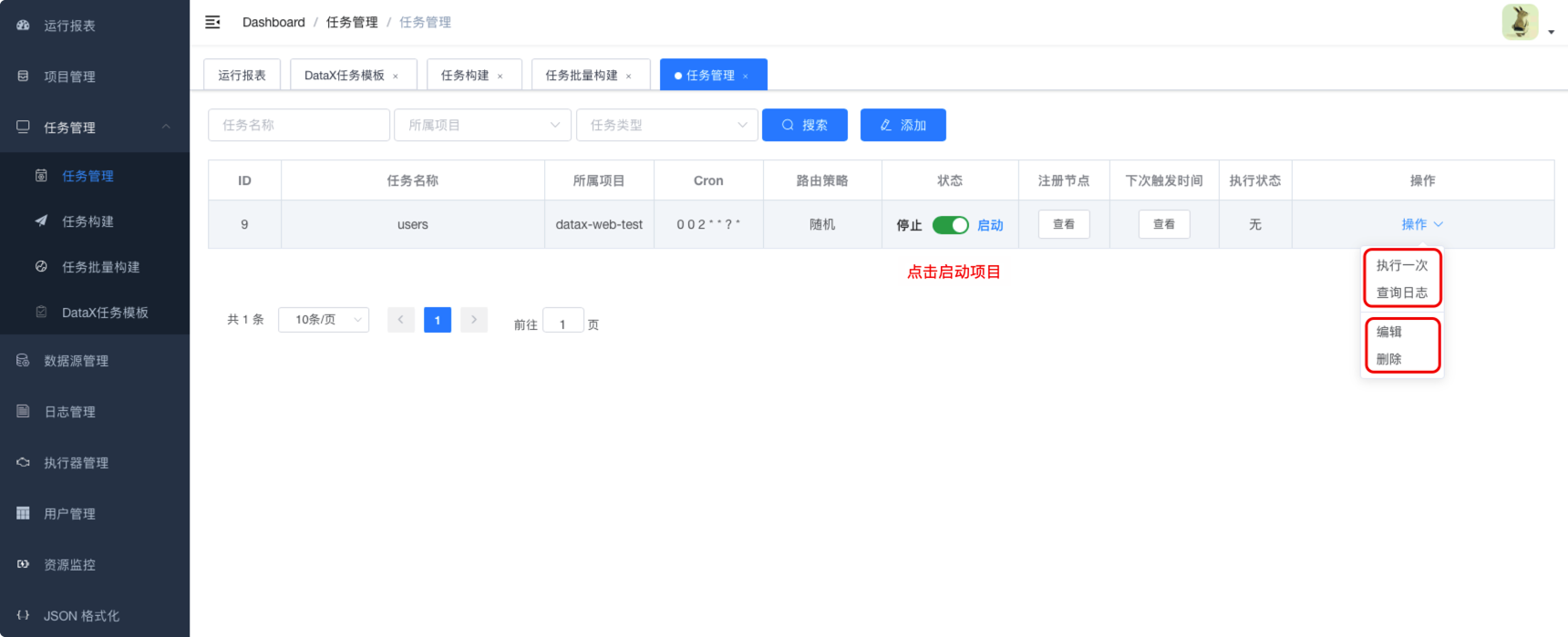
6.3. datax-web任务部署
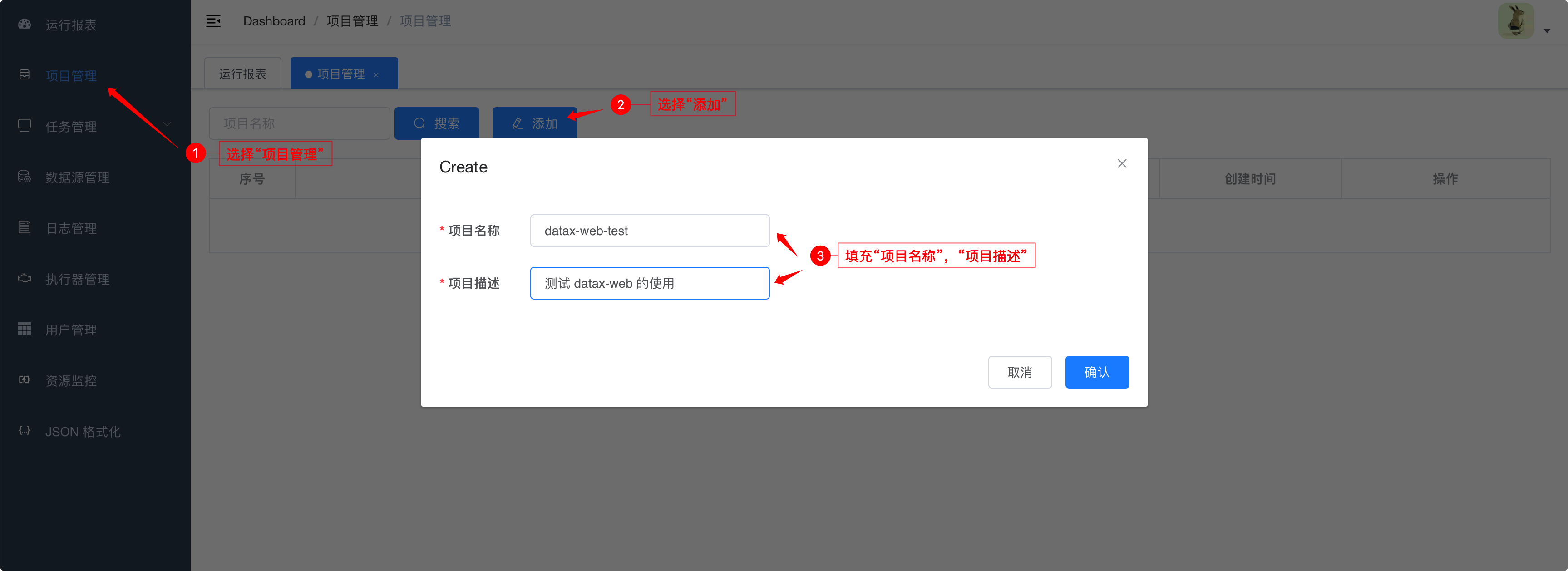
6.3.1. 创建项目
6.3.2. 执行器管理
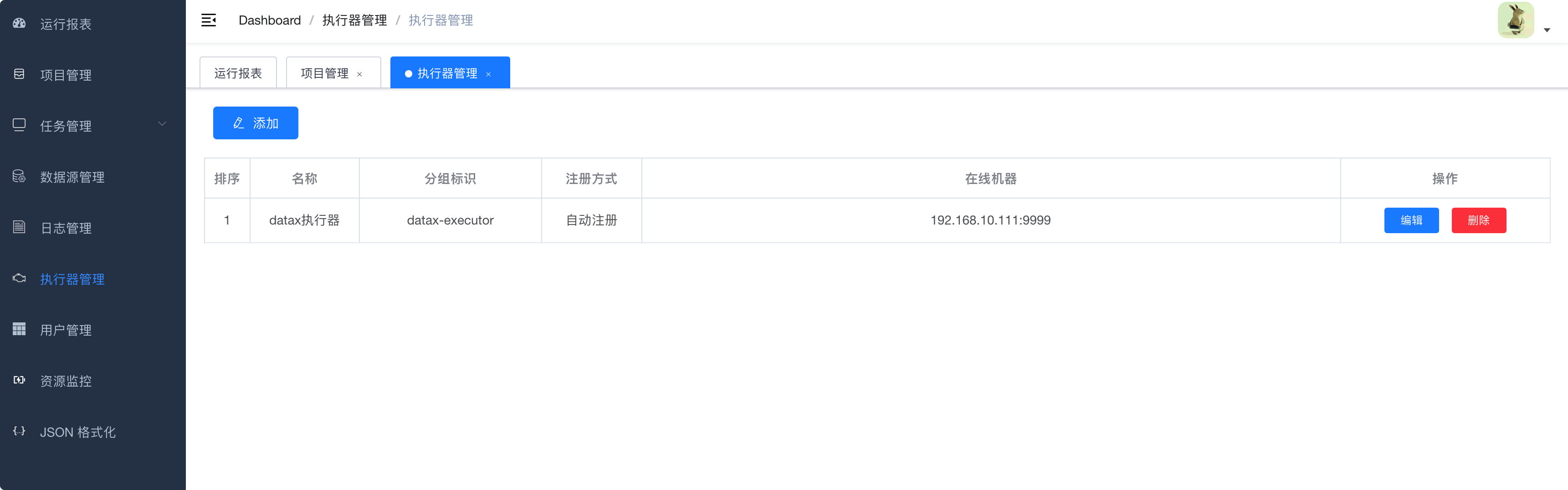
在这里会列举所有在线的Executor列表
6.3.3. 创建数据源
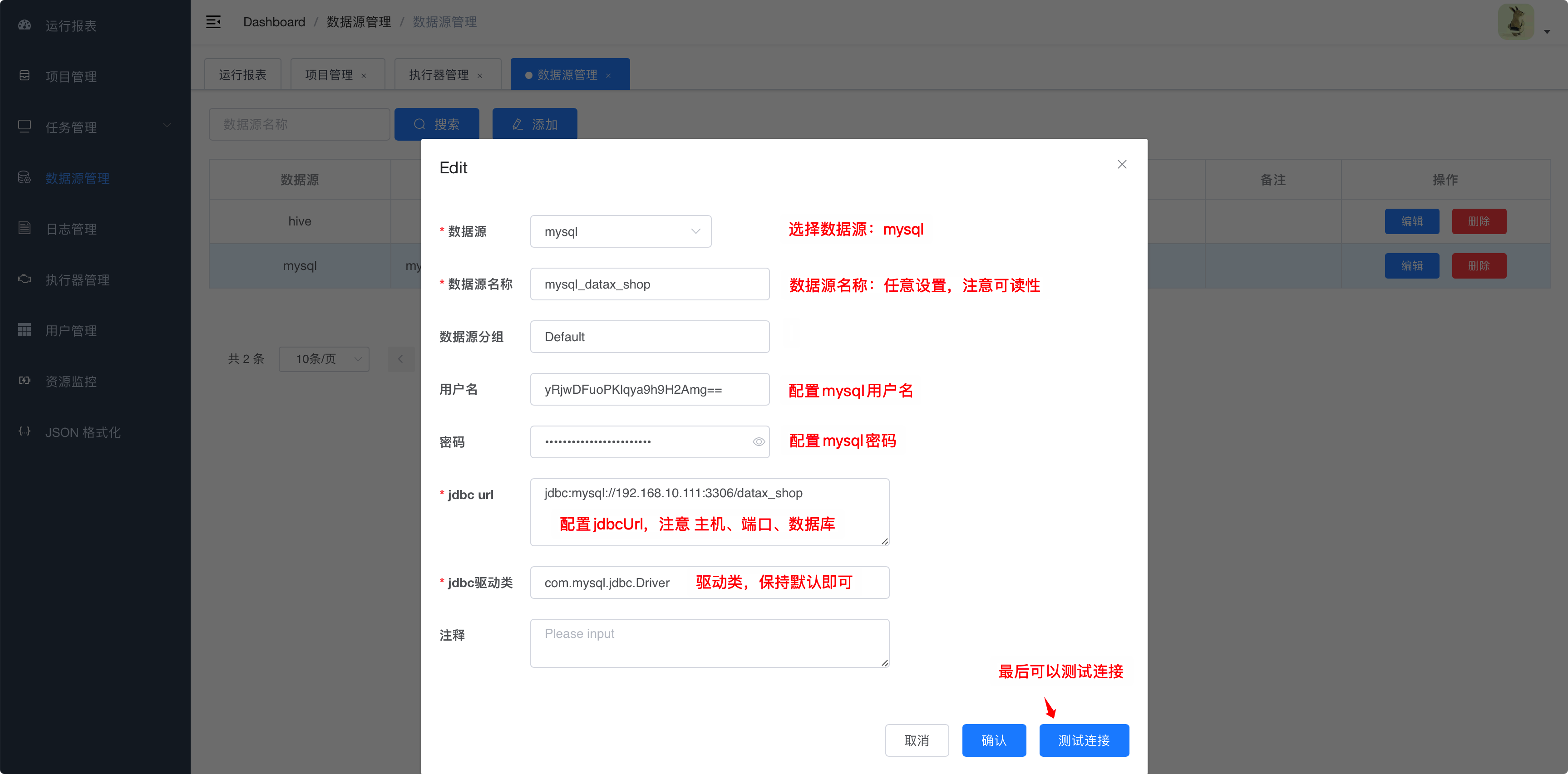
6.3.3.1. mysql数据源
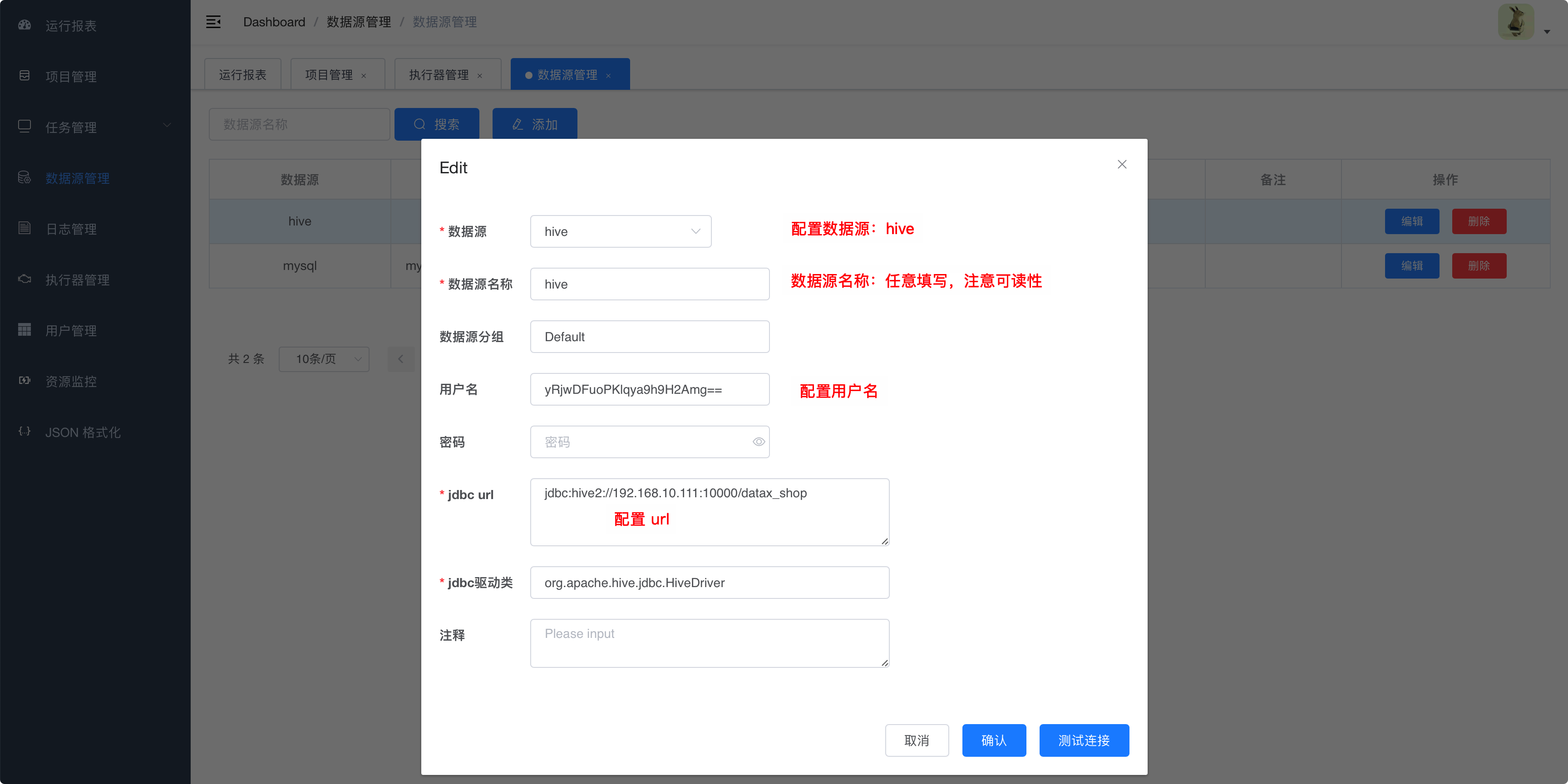
6.3.3.2. hive数据源
datax-web是通过ThriftServer连接到Hive的。因此需要保证Hive的
hiveserver2服务是开启的状态。
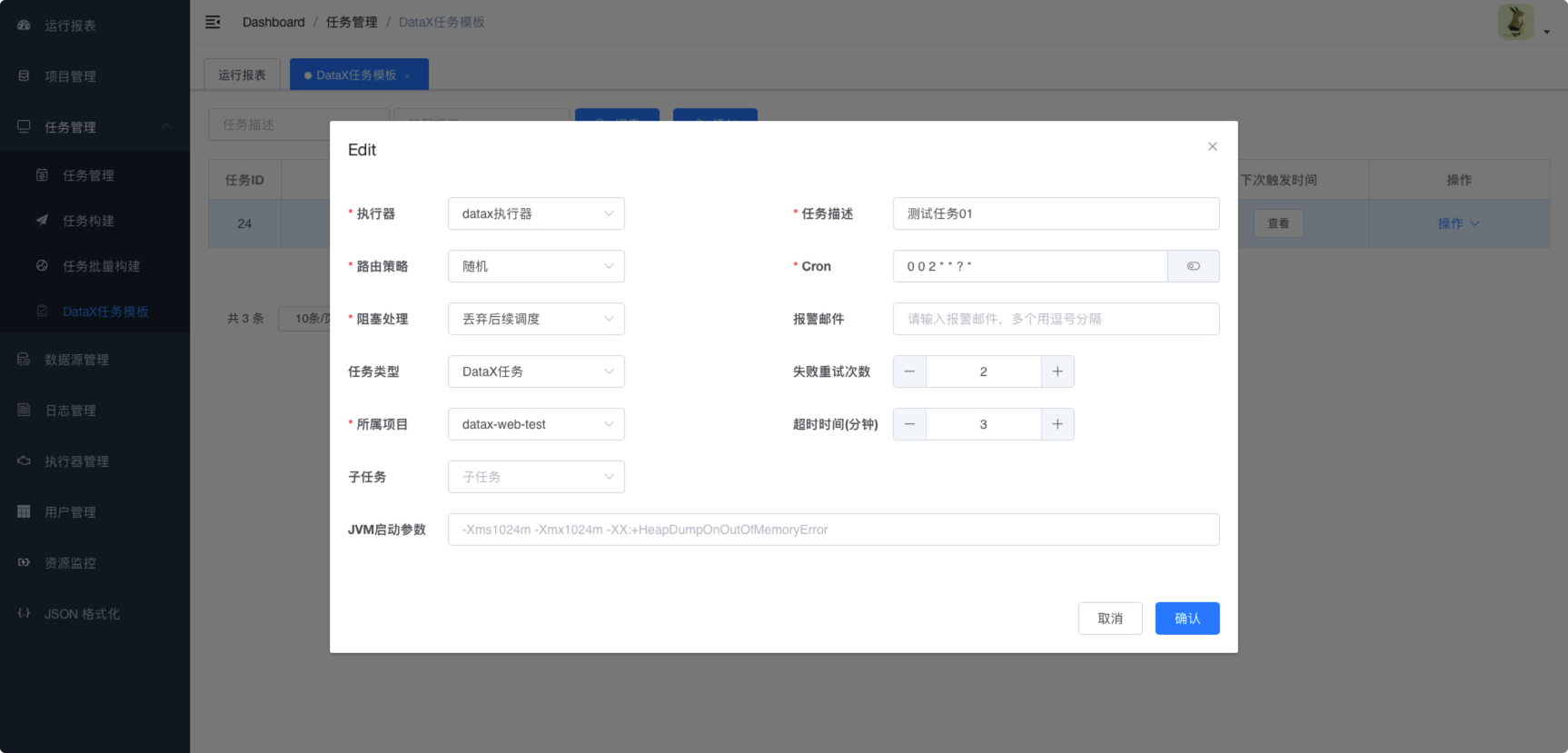
6.3.4. 创建任务模板
6.3.5. 任务创建
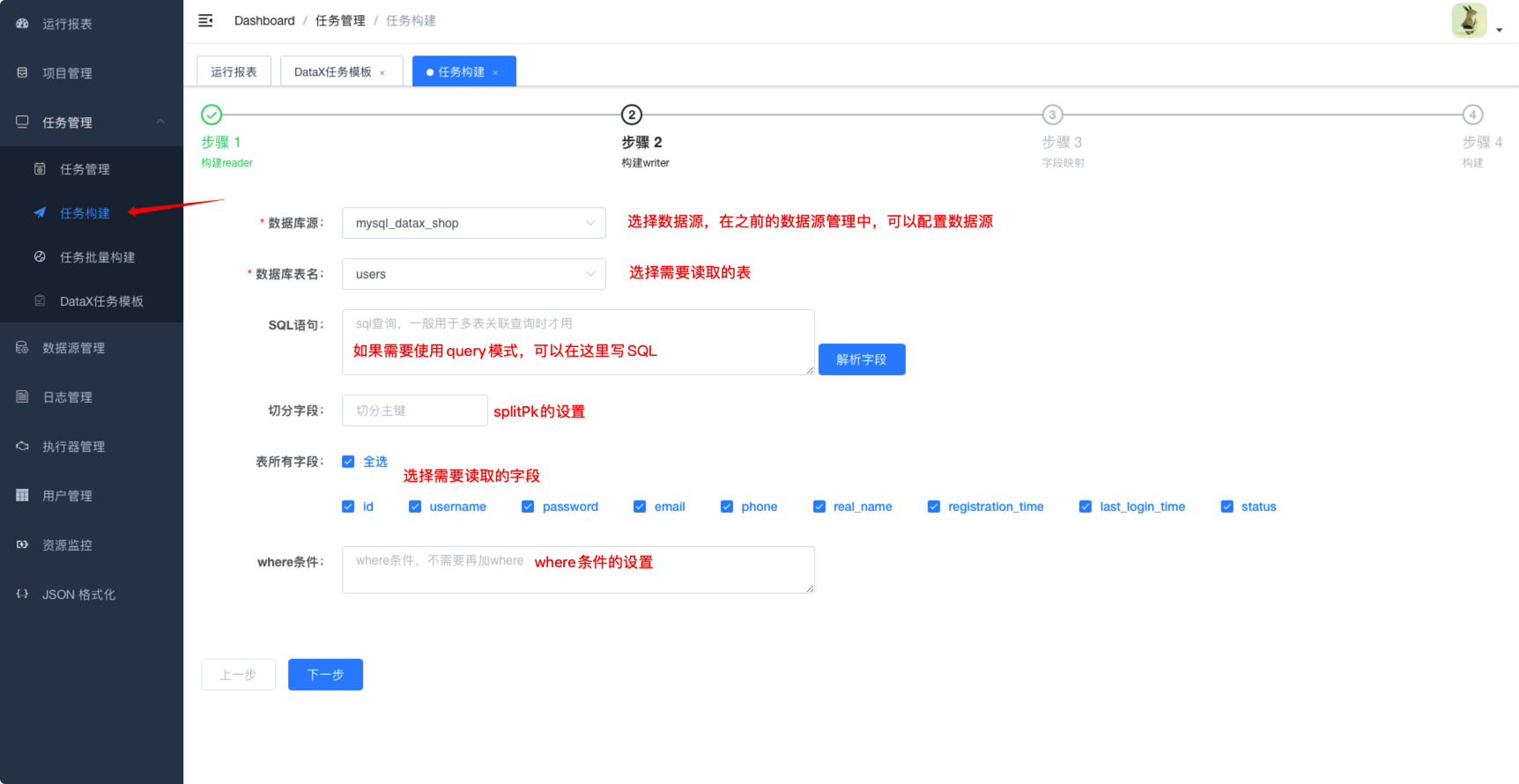
6.3.5.1. 构建reader
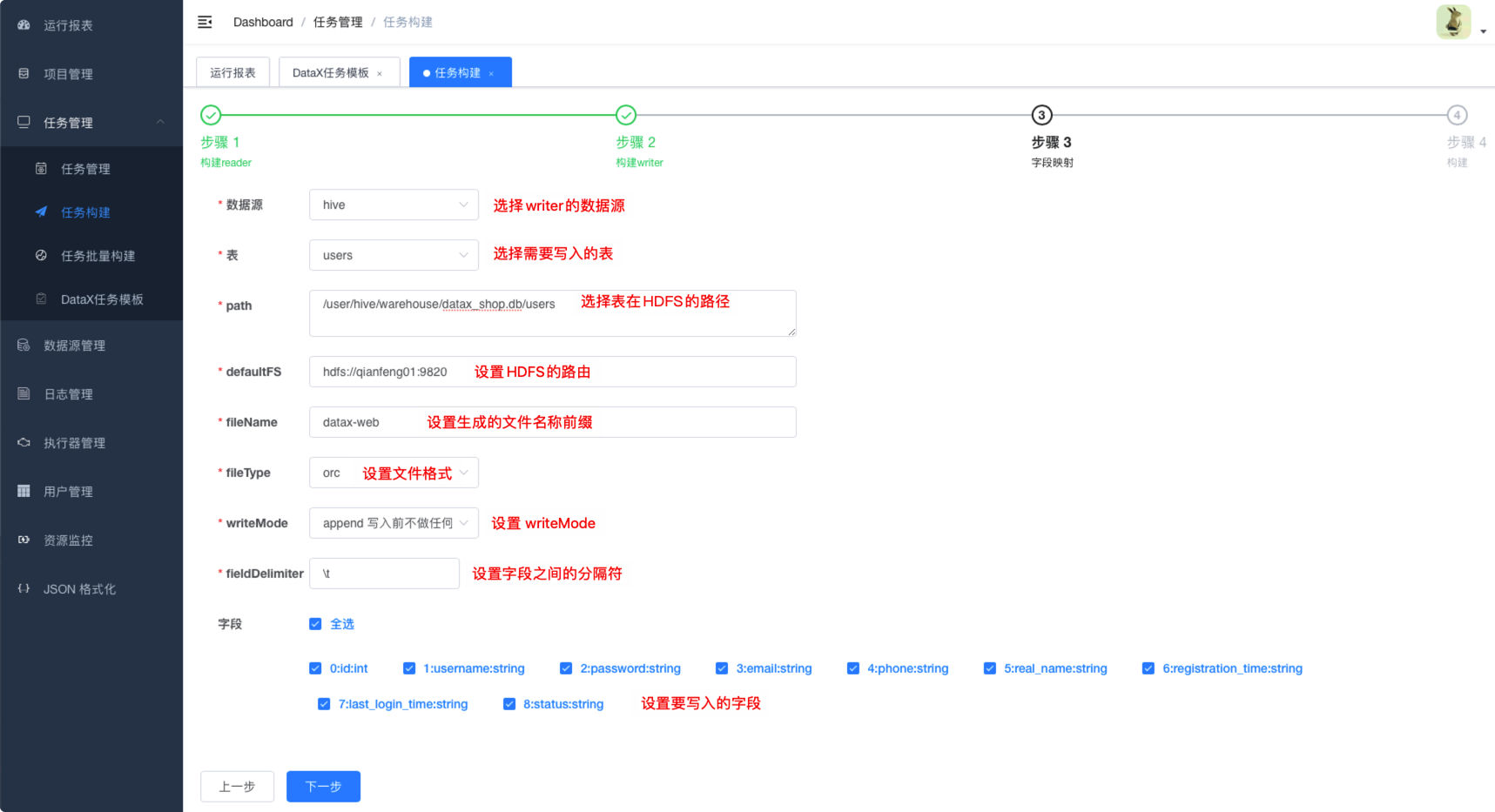
6.3.5.2. 构建writer
6.3.5.3. 设置字段映射

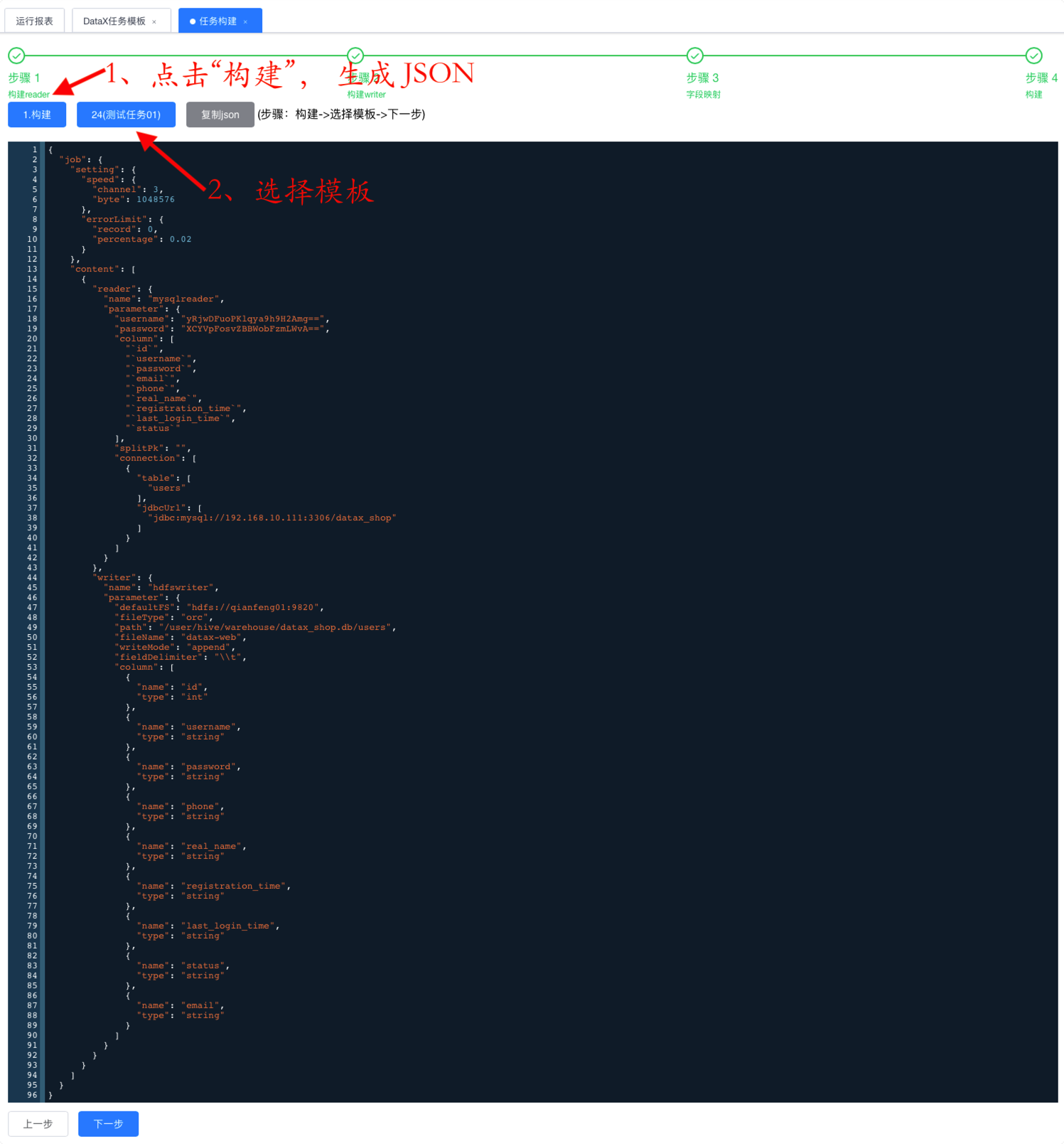
6.3.5.4. 构建
6.3.6. 批量任务创建
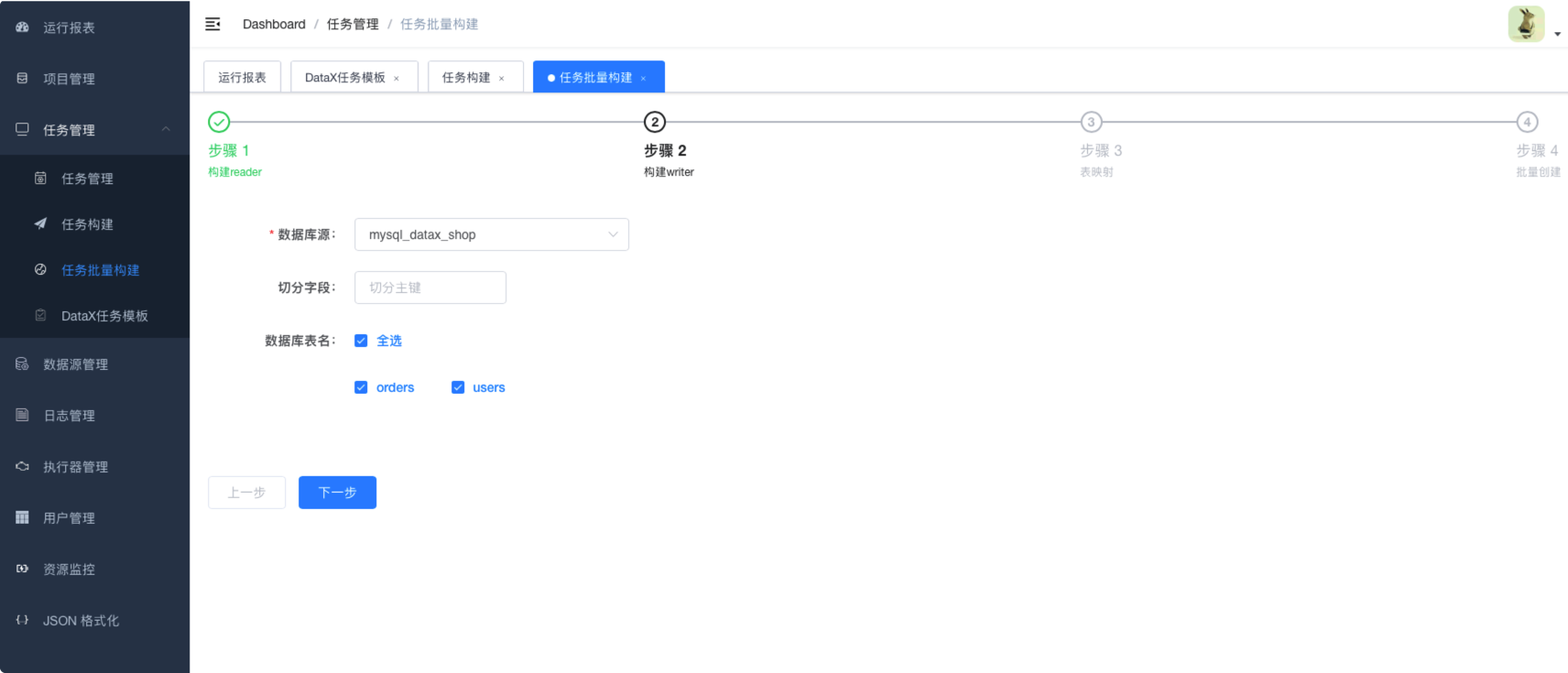
6.3.6.1. 构建reader
6.3.6.2. 构建writer
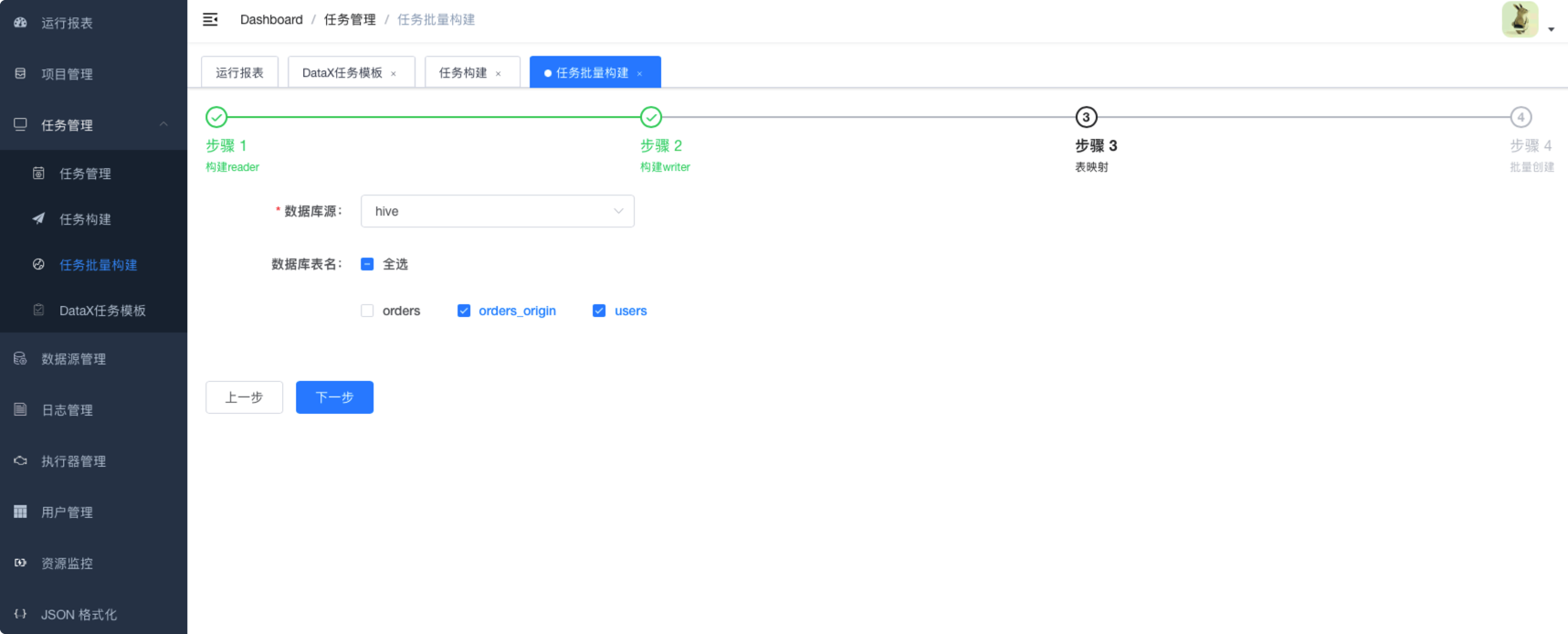
6.3.6.3. 字段映射
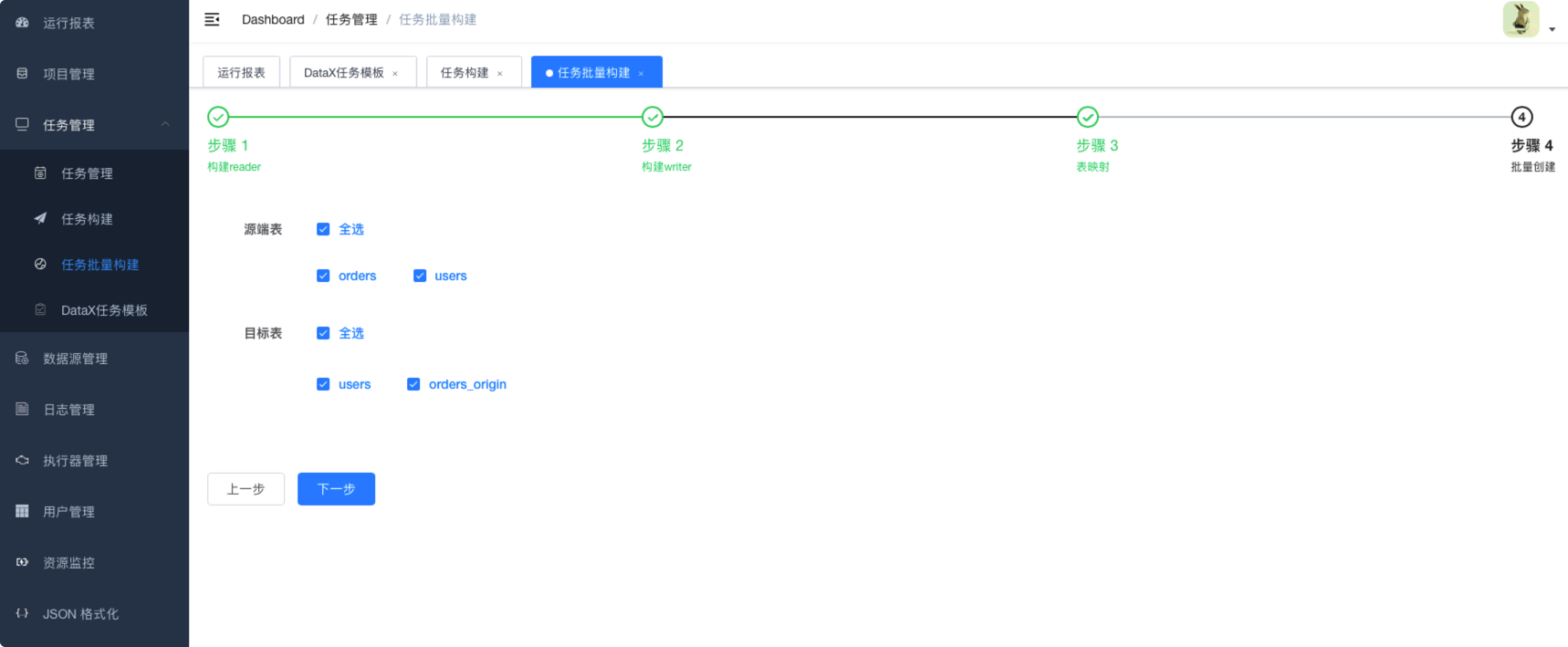
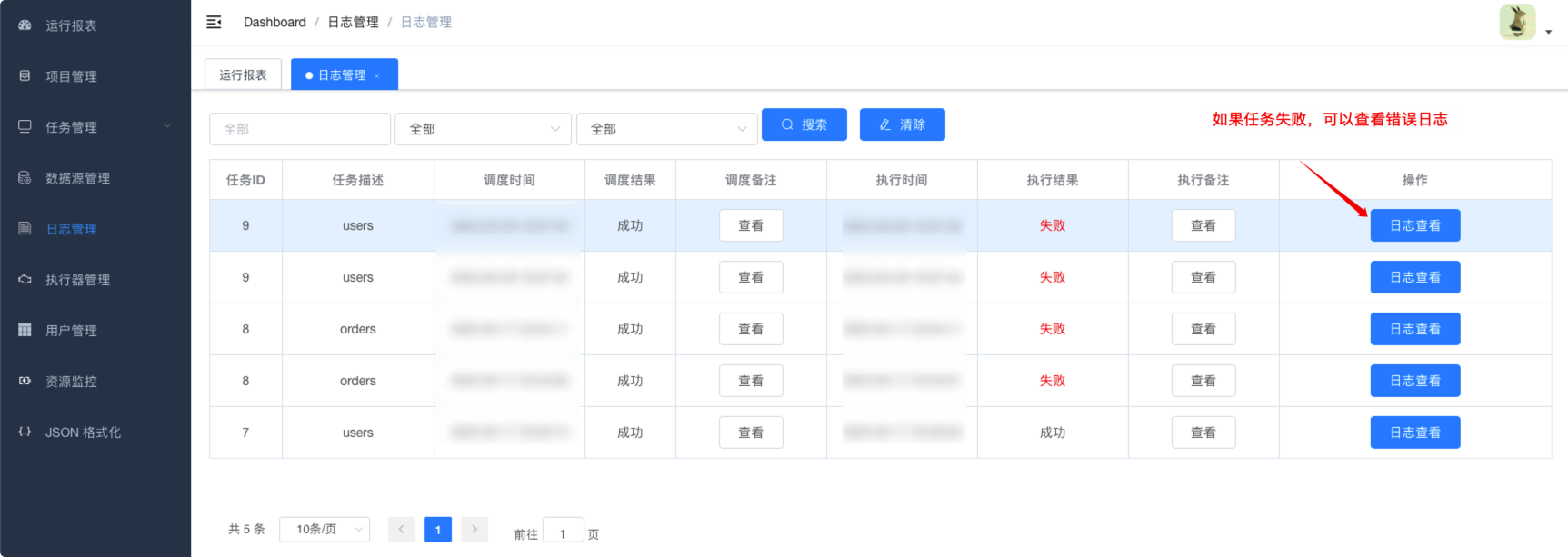
6.4. datax-web任务管理